
In the first half this year, both inferencing deployment patterns and an emerging AI application architecture have begun to standardize and provide a better perspective on future impacts to everything from the network to application delivery and security. We are confident in the results of our recent AI-focused research that inferencing will be deployed both on-premises and in the cloud (self-managed pattern) as well as consumed via cloud provider offerings (cloud-hosted pattern) and as a service (inference as a service pattern).
However, emerging AI architecture relies heavily on retrieval augmented generation (RAG), which incorporates data sources (knowledge graphs and vector databases) into the application architecture. Research indicates that “70% of companies leveraging GenAI use tools and vector databases to augment base models.” (Databricks, 2024)
The consequence of this architectural pattern is four-fold.
- Expands the number of modern application workloads in the enterprise.
- Dramatically increases the number of APIs in need of security.
- Raises the strategic relevance of the E-W data path to application delivery and security technologies.
- Introduces a new tier into application architectures—the inferencing tier. This is the “model” tier referenced by early AI tech stacks, but when operating AI applications it helps to differentiate between a model in training (development process) and a model in operation (run process).
It is important to note that 90% of the challenges organizations face with respect to AI architecture are not new. Changes to meet expectations for visibility, rate limiting, routing, etc. are incremental to existing capabilities that most enterprises already possess.
Of all the capabilities needed to deliver and secure AI applications, I estimate a mere 10% are net new, and nearly all of those are related to prompts and the unstructured nature of AI application traffic. It is this 10% giving rise to new application services such as prompt security, prompt management, and prompt optimization along with data security-related functions. F5 has already demonstrated commitment to addressing these needs through partnerships with Portkey and Prompt Security.
This is also where we’re seeing the introduction of AI gateways. Now, the definition of AI gateway and the capabilities it brings to the market vary depending on who is offering the “thing” but like API gateways, AI gateways tend to bring together security and application routing capabilities into a single, strategic point of control for organizations. But again, the capabilities in the “thing” are mostly incremental new capabilities specific to AI traffic and the rest are extant.
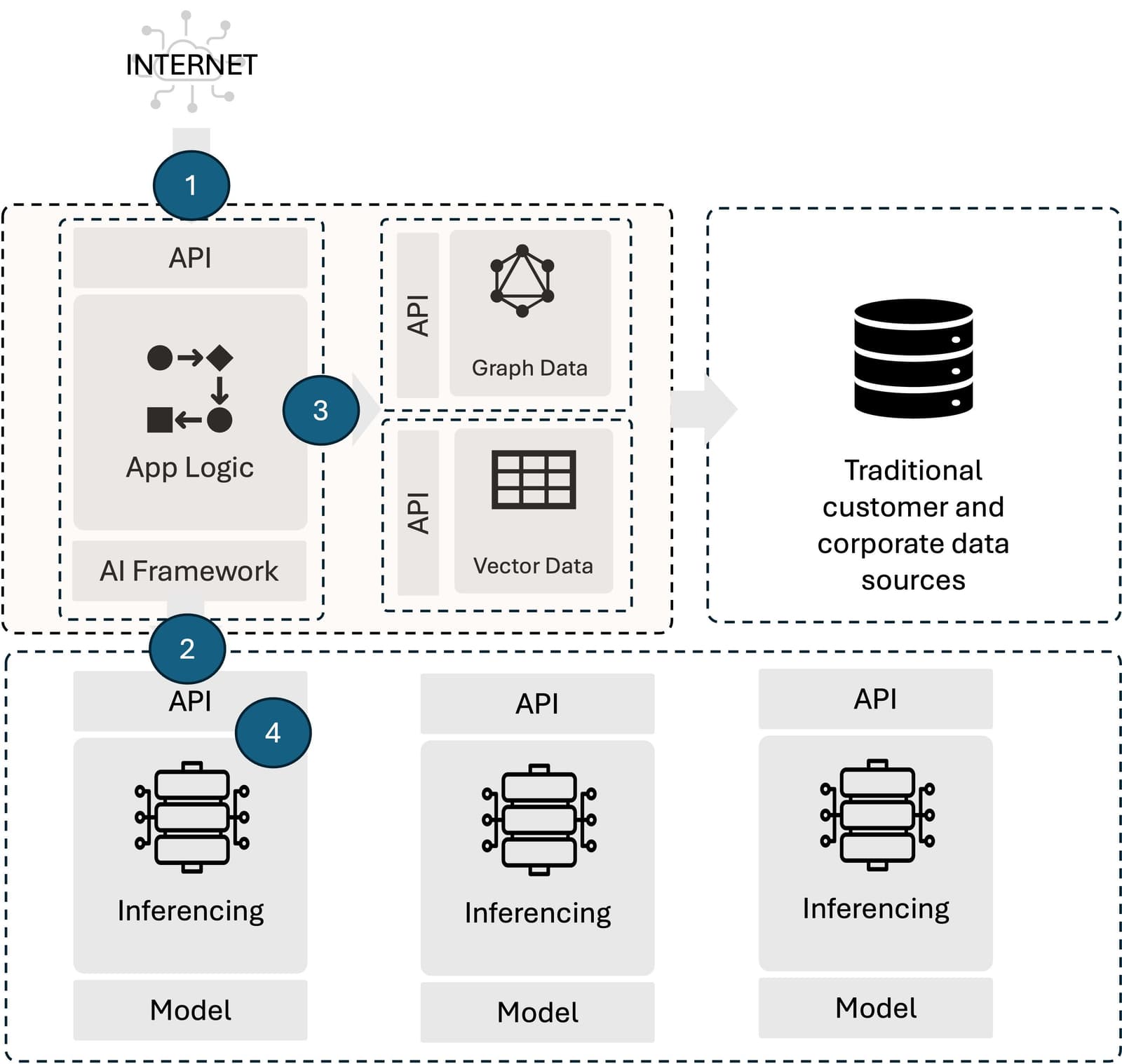
The really interesting thing, to me, is the new tier, because that’s where new and existing application delivery and security capabilities are going to be needed.
In fact, the introduction of a new tier is causing a new data center architecture to emerge with infrastructure capable of delivering the compute, storage, and network resources required to run AI inferencing at scale. This tier is where things like AI network fabrics or AI factories or whatever we’re going to call them are emerging. Irrespective of the name, this new infrastructure construct includes the ability to operate existing infrastructure constructs on new hardware systems. That’s #4 in the nifty diagram provided.
But there’s some new capabilities needed at #2, as well. While the bridge here is a fairly standard N-S data path with an obvious need to scale, secure, and route API traffic (yes, that API is for inferencing but it’s still an API) we are likely to see new load balancing algorithms—or at least, new decision criteria incorporated into existing algorithms—at this juncture.
For example, token counts and context windows are particularly important to understanding performance and the load a given request puts on the receiving system, not to mention the impact of token counts on cost. Thus, it’s no huge leap of logic to recognize that these variables may become part of any load balancing/traffic routing decision made at #2.
Point #4 is perhaps the most interesting because it returns us to the days of leveraging hardware to offload network tasks from servers. Yes, this is the return of the “let servers serve” approach to architecture. In the modern world, that means leveraging DPUs as a holistic system on which application delivery and security can be deployed, leaving the CPU on the inferencing server to, well, inference. It’s a pattern we’ve seen before, and one that will successfully address any issues with scaling (and thus, performance) inferencing services.
The impact of AI architecture on application delivery and security is both mundane and monumental. It is mundane because the challenges are mostly the same. It is monumental because it introduces additional points in architecture where organizations can strategically address those challenges.
How the industry responds to both the mundane and the monumental will shape the future of application delivery and security.
About the Author

Related Blog Posts

Multicloud chaos ends at the Equinix Edge with F5 Distributed Cloud CE
Simplify multicloud security with Equinix and F5 Distributed Cloud CE. Centralize your perimeter, reduce costs, and enhance performance with edge-driven WAAP.

At the Intersection of Operational Data and Generative AI
Help your organization understand the impact of generative AI (GenAI) on its operational data practices, and learn how to better align GenAI technology adoption timelines with existing budgets, practices, and cultures.
Using AI for IT Automation Security
Learn how artificial intelligence and machine learning aid in mitigating cybersecurity threats to your IT automation processes.
Most Exciting Tech Trend in 2022: IT/OT Convergence
The line between operation and digital systems continues to blur as homes and businesses increase their reliance on connected devices, accelerating the convergence of IT and OT. While this trend of integration brings excitement, it also presents its own challenges and concerns to be considered.
Adaptive Applications are Data-Driven
There's a big difference between knowing something's wrong and knowing what to do about it. Only after monitoring the right elements can we discern the health of a user experience, deriving from the analysis of those measurements the relationships and patterns that can be inferred. Ultimately, the automation that will give rise to truly adaptive applications is based on measurements and our understanding of them.
Inserting App Services into Shifting App Architectures
Application architectures have evolved several times since the early days of computing, and it is no longer optimal to rely solely on a single, known data path to insert application services. Furthermore, because many of the emerging data paths are not as suitable for a proxy-based platform, we must look to the other potential points of insertion possible to scale and secure modern applications.