
If you’re going to automate all the things, you’re going to want to go declarative. Here’s why.
We’ve been pounding the declarative drum for quite a while whenever we talk automation, particularly with respect to NetOps and application services. But we really haven’t dug into why it’s important and what the benefits are. I aim to rectify that right now.
To refresh your memories, there are two models currently used to automate configuration and deployment of, well, everything.
The first is imperative, in which we tell the target system exactly how to do what we want to do. If you’ve ever opened up an SSH tunnel to a system and typed in a specific set of commands on the CLI, you’ve engaged in the imperative model of configuration.
The second (and preferred) is declarative, in which we tell the target system what to do, but not how. This is the model embraced by most network automation solutions for a number of reasons, the most prominent being the overwhelming cost and time required to learn and integrate the hundreds of possible devices and systems that might be in a given environment.
So in an imperative model, we have to specific each command (or API call) required to configure a system. In a declarative model, we just specific key-value pairs (usually) that describe what we want and let some other system worry about the commands to make it so.
Easy peasy, lemon squeezy.
Now to answer the question as to why this is important. There are four primary benefits to adopting a declarative model when you’re moving to automate all the things.
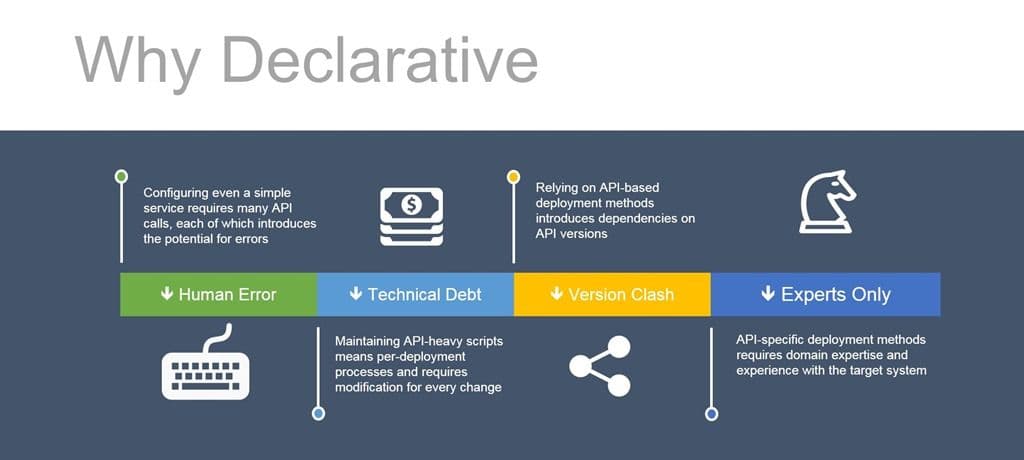
1. Reduce Human Error
We know that something like 22% of outage incidents in production occur because of human error. Some fairly high-profile incidents, which I’ll not hash out yet again, have been directly traced to simple human error. In an imperative model, relying on API calls, each one is a potential incident waiting to happen. If you didn’t verify a variable, or forgot to check for an error code, or a hundred other possible scenarios, you may experience a resume-generating event. That’s a bad thing.
A declarative model is based on a template or configuration file of some kind that will be parsed and validated before API calls are used to execute against it. While you can certainly still mess up a configuration file or template, the opportunities to do so are limited because you’re reducing the code required. And less code generally means fewer opportunities to make a mistake.
2. Reduce Technical Debt
Technical debt is that fun metaphor we picked up from development that reminds us of the long-term cost of our choices. Technical debt mounts with imperative models in several ways. First, there’s the coupling of the scripts to the API of our target system. That API isn’t likely to support anything else, which means we’re developing scripts on a per-system basis. The configuration steps will also likely vary from app to app – not everything is HTTP, and not every HTTP-based application requires exactly the same service configuration. So now we’re building scripts on a per-app, per-system basis. That’s a lot of scripts, and a lot of debt mounting based on that choice.
Conversely, a declarative method can use the same deployment process script and system. While the template/configuration will still likely be application and system-specific, it’s a single file. It eliminates the complexity and number of scripts and thus dramatically reduces technical debt. The reality is there’s always going to be some debt incurred by our choices; minimizing it is the goal.
3. Eliminate Version Clashes
When you tie your configuration and deployment processes to an API, you are tied to that version of the API. There are plenty of communities on the Internet with hostile, angry developers sounding off about changes to an API and the work required to change their app. The same thing can (and will) happen with network and application services. So if you’re tied to one version of the API and something changes, guess what? You’re going to be updating (or perhaps rewriting) scripts until the cows come home*.
But if you’ve adopted a declarative model, you’re likely going to be able to ignore any changes to the API. After all, you’re not using the API to tell the system how to deploy a service, you’re just telling it what needs to be deployed.
4. Reduce Domain Expertise Requirements
Let’s face it, if I’m going to use an API for a network or application service, I have to understand the system. If you don’t know the difference between a virtual IP and a virtual server, well, you’re in trouble already and we’ve barely gotten to nodes versus members. Imperative, API-based methods require you understand the target system well-enough to navigate its configuration.
Using a declarative model, you need less expertise in the target system, which means developers and DevOps alike are more likely to be able to use the method to self-service applications. You’ll still need experts, of course, but the demands on consumers of the services is lessened and spreads out the burden of provisioning and deployment across a broader set of constituents.
There are other reasons why you’d want to adopt a declarative model for your NetOps automation efforts, but these four are the most compelling. That’s because they benefit NetOps, the business, and the broadening constituents who need self-service access to the network and application services that make apps go faster and safer.
About the Author

Lori MacVittie is a Distinguished Engineer and Chief Evangelist in F5’s Office of the CTO with deep expertise in application delivery, automation strategy, and infrastructure. She is known for turning complexity into clarity whether she’s defining guardrails for AI agents, dissecting brittle multicloud architectures, or probing the limits of scalable systems. She brings more than thirty years of industry experience across application development, IT architecture, and network and systems operations. Before joining F5, she served as an award-winning technology editor. MacVittie holds an M.S. in Computer Science and is a prolific author whose publications span security, cloud, and enterprise architecture. She is also an avid tabletop and video gamer with unapologetically strong opinions about cheese.
More blogs by Lori Mac VittieRelated Blog Posts

Secure-by-design storage for agentic AI: Why runtime visibility plus traffic control matters
Learn how F5 is collaborating with NVIDIA to help protect agentic AI with secure-by-design AI infrastructure, runtime visibility, and traffic control.

F5 joins the Dell AI Ecosystem Program to help enterprises operationalize AI
F5 joins the Dell AI Ecosystem Program to help enterprises deploy production AI with greater performance, security, and control.

Why sub-optimal application delivery architecture costs more than you think
Discover the hidden performance, security, and operational costs of sub‑optimal application delivery—and how modern architectures address them.

Architecting for AI: Secure, scalable, multicloud
Operationalize AI-era multicloud with F5 and Equinix. Explore scalable solutions for secure data flows, uniform policies, and governance across dynamic cloud environments.

AppViewX + F5: Automating and orchestrating app delivery
As an F5 ADSP Select partner, AppViewX works with F5 to deliver a centralized orchestration solution to manage app services across distributed environments.

F5 NGINX Gateway Fabric is a certified solution for Red Hat OpenShift
F5 collaborates with Red Hat to deliver a solution that combines the high-performance app delivery of F5 NGINX with Red Hat OpenShift’s enterprise Kubernetes capabilities.