エッジネイティブ アプリケーションにおけるクラウドの役割

クラウドの出現によってクラウド ネイティブ アプリケーションが生まれたのと同様に、エッジが一連のエッジ ネイティブ アプリケーションを推進していることは驚くべきことではありません。
ただし、これらのアプリケーションはエッジにのみ存在するわけではありません。 それどころか、IT (情報技術) と OT (運用技術) の融合が進むにつれて、クラウドやデータセンターにあるアプリケーションも活用する新しいアーキテクチャ パターンが生まれています。
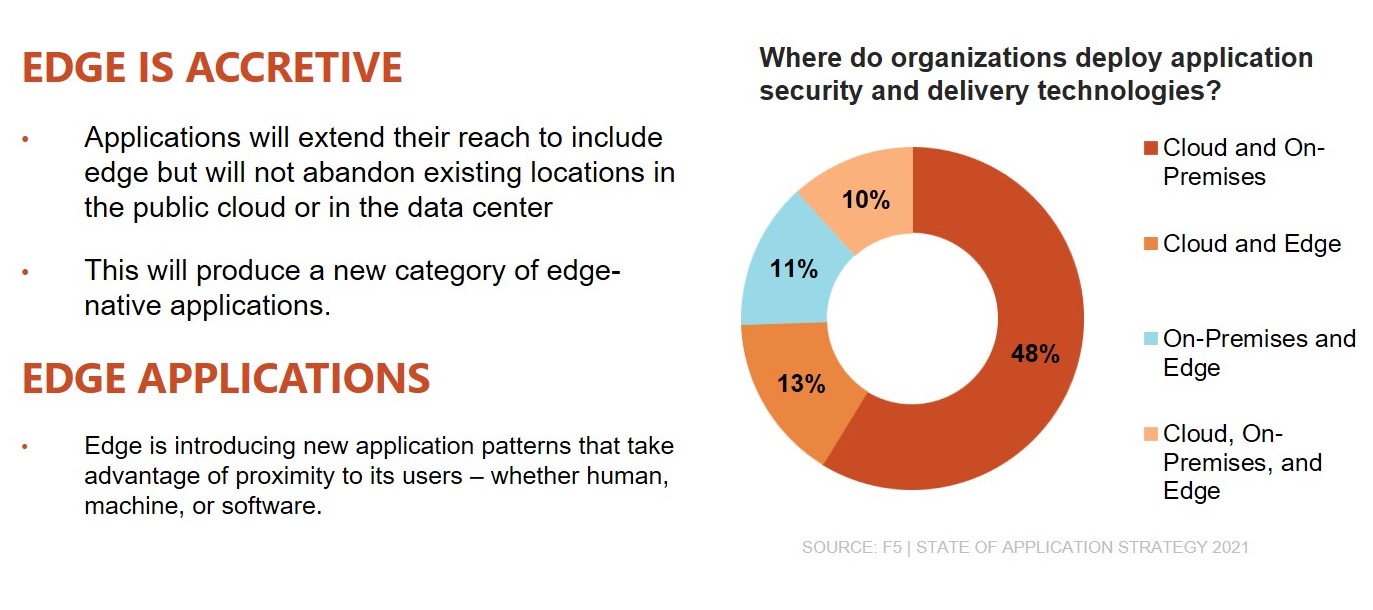
現在、組織がアプリケーション セキュリティと配信テクノロジを導入している場所を考慮すると、このことを示す先行指標がわかります。 組織の半数未満 (41%) が、これらのテクノロジーをホストするために 1 つの場所のみに依存しています。 平均は 2 を少し超え、正確には 2.11 です。 現在最も可能性の高い組み合わせはクラウドとオンプレミスですが、10 社中 1 社はすでにデータ センター、クラウド、エッジの 3 つの場所すべてを活用しています。
これは、ほとんどの一般家庭で見られる平均 10 個の接続されたデバイスをサポートするように構築されたアーキテクチャの場合に特に当てはまります。 実際、一般的なエッジ アプリケーションを見ると、クラウドとエッジ、ノードとエンドポイントが混在していることがわかります。
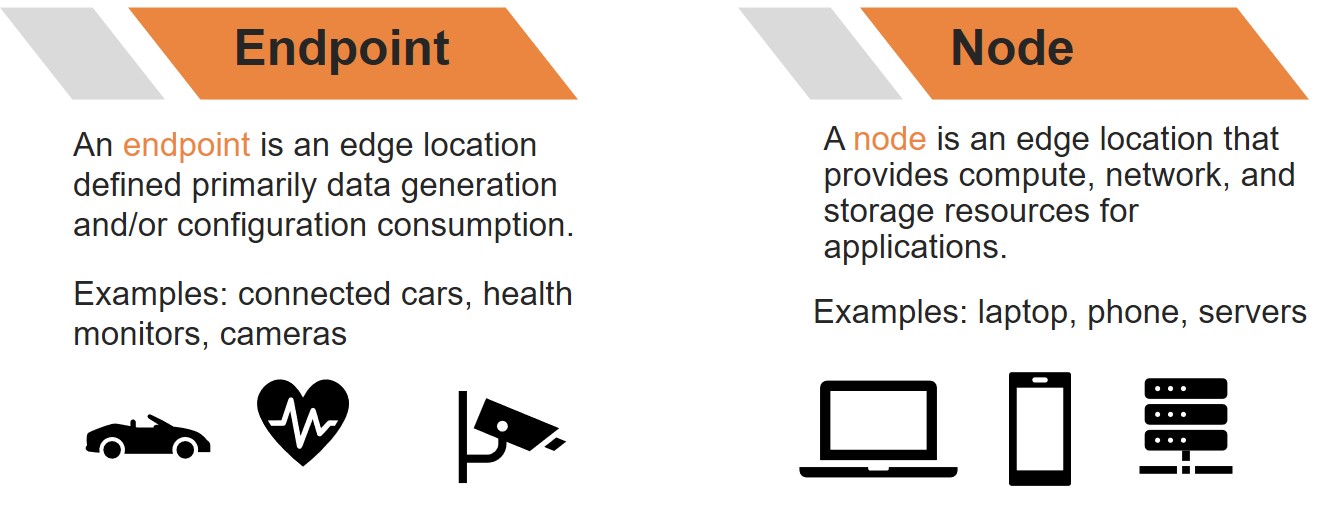
エッジ ノードとエッジ エンドポイントは、それぞれの固有のプロパティに基づいて区別されます。 これにより、各場所には独自の機能と制約があるため、「エッジ ネイティブ アプリケーション」を構成する特定の機能に対する責任を明確にすることができます。 たとえば、通常、エッジ エンドポイントは大量のデータの保存をサポートしていません。 エッジノードはそうかもしれませんし、データセンター/クラウドは確かにそうでしょう。 これらの機能と制約は、各場所の強みを活かしてプロバイダーと消費者の両方にメリットをもたらすエッジネイティブ アプリケーションを形成するのに役立ちます。
これが、クラウドとデータセンターがエッジネイティブ アプリケーションで重要な役割を果たす根本的な理由です。
たとえば、私の Plex メディア サーバーを考えてみましょう。 私の家にはローカル サーバー (エッジ ノード) があり、スマート TV (エッジ エンドポイント) にアプリがあります。 エッジ ノードは、課金とアカウント管理、リモート アクセス、ソフトウェア更新のためにクラウドベースの Plex サービスと通信します。 アプリケーション全体の改善に役立つ使用状況とパフォーマンスを説明するその他の会話とデータ交換が 2 つの間で行われます。

課金機能やアカウント管理機能がエッジ エンドポイントどころかエッジ ノードに存在することはまったく意味がありません。 同様に、Plex サービスにデジタル コンテンツのローカル リポジトリへのアクセス権を与えるのは効率的 (または安全) ではありません。 むしろ、その責任はエッジ ノード上で実行されているローカル メディア サーバーに委ねられます。
多くの点で、このパターンは、従来の(レガシー、ビンテージ、レトロ、成熟した、あるいは「時代以前」の婉曲表現)アプリケーションに最新のインターフェイスを提供するための近代化の取り組みによって生み出されるパターンと変わりません。 世紀の変わり目に Web ベースのアクセスを提供するために、テキストベースのシステムのスクリーン スクレイピングを検討してください。 あるいは、従来のトランザクション システムに依存するモバイル バンキングを容易にするために API を使用することもできます。 近代化の取り組みにより、データセンター、クラウド、エッジの境界を越えてシステムとアプリケーションに責任を割り当てるアプリケーション パターンが生成されることがよくあります。
このような決定は、接続されたモノ、センサー、その他のエッジ アプリケーションに対して毎日行われています。 これらの決定は、共通のエッジネイティブ アプリケーション パターンとして現れます。
ほぼすべてにクラウド/データセンターに存在する機能が含まれています。
クラウド コンピューティングが登場したときにデータ センターは時代遅れだと急いで宣言したのとは異なり、エッジが登場している今、クラウドについて同じことを宣言する人はおそらくいないでしょう。 それどころか、クラウドとデータセンターは、エッジネイティブ アプリケーションにおいて引き続き重要な役割を果たします。