AI agents are changing how applications interact with infrastructure. Unlike traditional systems, agents carry their own goals, context, and decision logic inside each request—what to do, how to recover, and what success looks like. This shift breaks long-held assumptions about traffic management and forces a rethink of enterprise infrastructure. Static routing, pooled resources, and centralized policy no longer suffice in a world of per-request autonomy.
Agent architectures demand that infrastructure evolve from reactive execution to real-time interpretation of embedded intent. Enterprises that recognize this shift can prepare without discarding existing investments by adapting them instead.
AI agents are not simply intelligent applications. They represent a structural shift in how applications operate, decide, and adapt. Unlike traditional systems, agents don’t just respond to traffic policies, they bring their own. Each request they send carries not only data, but embedded logic: what should happen, how fallback should behave, and what success looks like.
This shift moves decision-making from static control planes into the runtime itself. It collapses the long-held separation between control and data planes, forcing traffic infrastructure—load balancers, gateways, proxies—to become interpreters of per-request policy rather than passive executors of preconfigured routes.
This paper explores how agent architectures break key assumptions in traffic engineering, from health checks and fallback logic to observability and security enforcement. It explains why traditional constructs like static pools and average-based health metrics are no longer sufficient in a world of per-request intent. And it makes the case that Layer 7 infrastructure must evolve or risk becoming commoditized plumbing, reliable, but strategically invisible. To adapt, organizations must rethink their traffic stack: making it programmable at runtime, context-aware, and aligned with agent-native protocols like Model Context Protocol (MCP). This includes retooling fallback logic, embracing semantic observability, and supporting enforcement of agent-originated policies. Emerging tools like real-time data labeling offer critical support for this shift.
In short, the future of traffic management isn’t just about delivering packets, it’s about executing purpose.
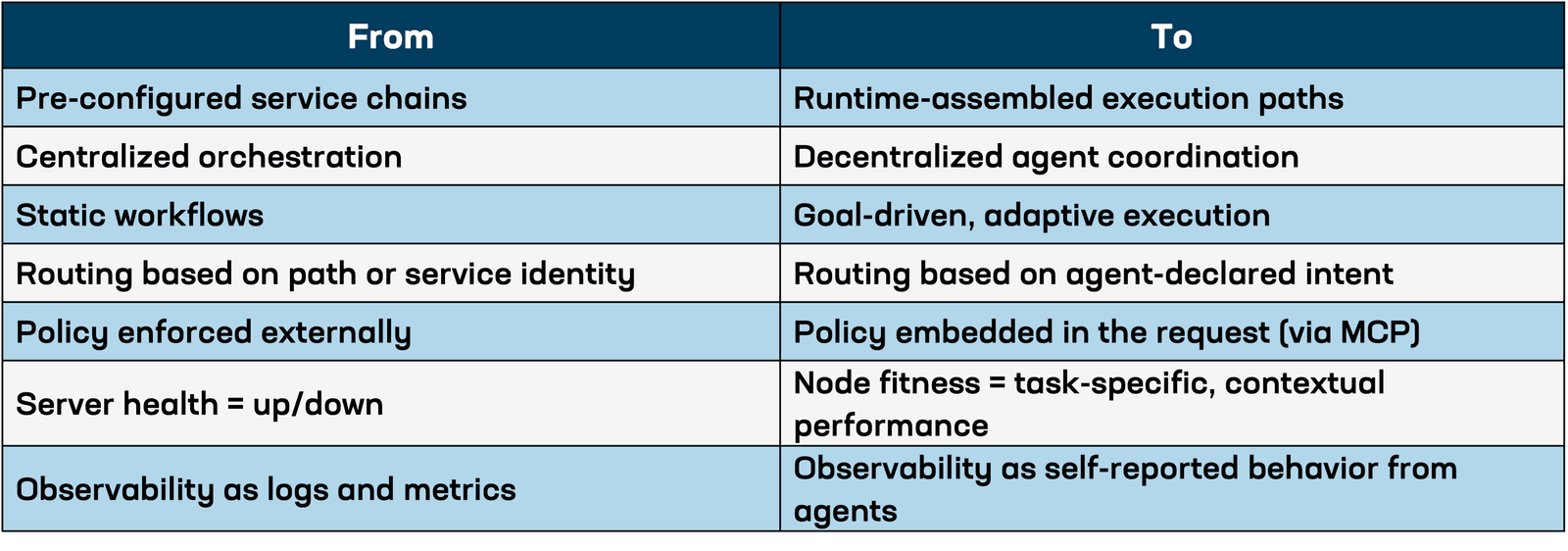
Agent architectures introduce a new operational model where autonomous, generative AI-powered components—called agents—perform goal-oriented tasks, make decisions in real time, and carry the context necessary to adapt their execution on the fly. These agents act much like service chaining does today, but without relying on pre-configured workflows. Instead, they determine the appropriate flow of execution at runtime based on goals, environmental state, and observed outcomes.
This shift represents a move away from traditional, centrally orchestrated systems with predetermined workflows to decentralized, dynamic systems capable of constructing execution paths in real time. It replaces the predictability of static microservice chains with fluid, responsive decision-making that is driven by live data and intent.
Agent-based systems are defined by the following:
Together, these shift the application landscape from something predictable to something adaptive and evolving.
Current traffic management systems are built around clear boundaries:
This model has worked well for decades, especially in service-oriented architectures and microservices environments. It assumes traffic flows can be modeled ahead of time, and that workloads follow predictable patterns.
Examples:
/api/login to one pool and /api/images to another.These systems rely on:
But agent-based systems introduce fluidity, autonomy, and self-directed logic that break these assumptions.
In agent architectures, the traditional separation between the control plane and the data plane begins to collapse. Agents don’t just execute requests; they embed the logic that defines what the request is, what conditions should trigger fallbacks, how success is measured, and even what the preferred route should be. These are traditionally control-plane concerns, but agents encode them in headers, tokens, or metadata that travel with the request itself through the data plane.
This convergence means the data plane can no longer act as a passive executor of centralized decisions. It must actively interpret policy on the fly. The request is no longer just a packet; it’s a policy artifact. As a result, load balancers, gateways, and routing layers must evolve from being reactive components to becoming real-time interpreters of agent-carried intent.
This shift undermines the core architectural assumption that the control plane is static and centralized. Instead, decision logic becomes distributed, portable, and personalized, flowing with each request and executed at runtime. This is not just a change in deployment; it is a change in where and how decisions get made.
This effectively finishes what Kubernetes began when it abstracted away the underlying infrastructure—networking, storage, even L4 traffic routing—and made it all "plumbing" behind a declarative control surface. It didn’t eliminate those layers, but it demoted them. They became invisible, automated, and subordinate to a new intent-driven system.
Agent architectures do the same thing, but to the entire stack, not just infrastructure.
To ground these disruptions in a real-world example, consider a local application delivery scenario:
Example: A regional e-commerce site uses an ADC to manage internal API traffic. An AI agent is assigned to optimize order fulfillment speed. It identifies that a specific API endpoint, e.g. /api/inventory/check, is experiencing degraded performance due to increased request complexity and backend database contention. Traditional load balancing algorithms, including "fastest response," fail to capture the nuance of this slowdown because they calculate performance as a generalized average over all responses for a given pool member, not on a per-task or per-call basis.
To meet its SLA, the agent reroutes these inventory-check requests to an alternate node group optimized for transactional queries. It does this by tagging each request with a context header, such as X-Task-Profile: inventory-sensitive. The load balancer, if properly configured, can interpret this and direct the traffic accordingly. However, because these nodes weren’t preassigned in the static pool associated with /api/inventory, traffic steering services must be capable of honoring agent-carried directives and dynamically resolving routing without relying on static constructs.
This scenario highlights the limitations of static constructs like pools and the need for context-aware, dynamically programmable traffic execution.
Agent-based systems break several foundational assumptions in traffic engineering:
Control/data plane convergence: Where once routing decisions came from static rules, they now come from the request itself. This collapses traditional enforcement logic.
Intent-based routing: Agents route traffic based on goals, not just endpoints. A single endpoint like /api/process might handle hundreds of different task flows, depending on agent directives.
Static pools become obsolete: Traditional pools assume fixed roles. But agents might require GPU access one moment, CPU optimization the next, making pool membership too rigid.

Fallbacks and failover become strategic: Failover used to mean “try the next server.” Now agents evaluate real-time performance, historical outcomes, and decide strategically how to proceed.
Traffic patterns emerge, not repeat: Agents create workflows on demand. You can’t predefine all paths, they form based on needs.
These disruptions challenge load balancers, gateways, and observability stacks to become responsive to fluid, real-time traffic logic.
Health and performance metrics have always been foundational to traffic management. Load balancing decisions depend on knowing whether a server is available, how quickly it responds, and how heavily it’s loaded. But in agent-driven systems, health isn't binary, and performance can't be averaged across broad categories. Metrics must reflect whether a target is suitable for a specific task, not just whether it's up.
Why it matters: Health metrics directly influence traffic steering, failover decisions, and performance optimization. In an agent-native environment, every request carries different intent and may require a different path or response guarantee. Traditional approaches can't satisfy this need because:
Example: A pool of API servers might all be "healthy" per health checks, yet one of them consistently fails to deliver responses under 100ms for X-Task-Profile: inventory-sensitive queries. An agent expecting this latency profile will perceive failure even if the infrastructure sees normalcy.
What’s needed:
Data labeling tools can play a critical role here, by labeling traffic in motion and capturing performance and context alignment. This allows systems to reason not just about what happened, but whether it met the goal of the actor that initiated it.
In traditional infrastructure, fallback behavior, such as retries, redirecting to backup nodes, or triggering circuit breakers, is implemented at the infrastructure layer. Load balancers, proxies, and gateways use predefined thresholds (e.g., timeouts, error ratios) to determine when to stop routing traffic to a target and attempt an alternate.
Agent architectures flip that logic.
Agents bring their own fallback strategies. They carry retry policies, escalation logic, and goal-centric priorities in the request itself. This introduces complexity and potential conflict with infrastructure-level failover mechanisms.
Why it matters:
Key risks:
Adaptation guidance:
X-Fallback-Order, X-Timeout-Preference).Example: An agent tasked with a real-time fraud check requests a response within 50ms. Its fallback logic prefers a cached partial result over a slow full query. Infrastructure unaware of this may still route to the full-service backend, creating user-visible lag. A more cooperative model would respect the agent's fallback priority and serve the faster degraded response.
As decision-making moves up the stack, fallback strategies must do the same. Circuit breakers and retry logic cannot remain static or opaque; they must adapt to agent-expressed preferences while preserving systemic safety and fairness.
While agent architectures shift decision-making and coordination into the request layer, the underlying infrastructure is still responsible for ensuring core system reliability. That means high availability (HA) and failover mechanisms at the infrastructure layer remain essential. In fact, they become even more critical as systems take on more dynamic, autonomous behavior.
Agents may direct traffic based on goals and context, but they still rely on the network to ensure that services remain reachable and resilient when things go wrong. Load balancers must detect unreachable nodes, failing services, or degraded environments and reroute traffic in real time regardless of the agent's fallback strategy.
Core responsibilities that do not change:
Agents may carry logic to determine “what should happen next,” but the load balancer still owns “how quickly we recover when a node is down.”
It is essential that adaptive, agent-aware routing logic does not come at the expense of operational stability. A well-instrumented infrastructure must retain:
In short, agent-driven architectures don’t eliminate the need for failover—they raise the stakes. The infrastructure must now respond faster, with greater context sensitivity, and without becoming a bottleneck to autonomous behavior.
The shift to agent-based architectures introduces a fundamental change in how traffic systems like load balancers and gateways must operate. Where traditional traffic systems made decisions based on preconfigured policy—often external to the request—agent-driven systems push that policy into the request itself. This is the foundation of what Model Context Protocol (MCP) enables: per-request execution of embedded policy.
We will call this model "policy in payload." Rather than having centralized systems parse every edge case, the agent encodes relevant policy decisions (such as fallback strategy, node preference, error tolerance, or privacy requirements) into each request. The infrastructure must then read, interpret, and act on those policy instructions in real time.
This new execution model transforms the role of traffic management components:
X-Route-Preference: gpu-optimized must forward traffic accordingly, even if that node wasn’t in the original pool.X-Intent, X-Context, or X-Goal. This shifts logic from preconfigured paths to dynamic, inline interpretation.Data labeling technologies and similar tools can support this shift by tagging and classifying real-time request context, making semantic routing and observability tractable.
AI agents won’t operate in isolation. They’ll interoperate with legacy systems, tap into traditional APIs, manipulate business logic in enterprise databases, and call functions hosted on monolithic backends and microservices alike. For enterprises, this means you don’t get to start fresh, you have to evolve.
Enterprise stacks are a blend of:
Agents must learn to work across all of it. And your infrastructure must learn to mediate that interaction in real time, with context-aware policy enforcement.
Agents don’t want five endpoints, they want one goal. Expose business functionality (e.g. “get order status”) via abstraction layers or API compositions that agents can consume via a single semantic entry point.
Prep step: Use API gateways or service meshes to consolidate task-oriented endpoints with clean input/output contracts.
Traditional logging focuses on method, path, and response time. But agents care about:
Prep step: Adopt semantic observability tooling that tags traffic with labels like X-Intent, X-Task-Type, and X-Agent-Outcome.
Agents bring fallback instructions, timeout preferences, and security requirements inside the request. Existing infrastructure discards this data.
Prep step: Extend traffic policies to parse and act on agent metadata (e.g., X-Route-Preference, X-Fallback-Order, X-Data-Class). Start with iRules or similar runtime scripting.
Agents are autonomous. You need to know:
Prep step: Integrate identity-based access and attribute-based policy controls (ABAC), not just IP whitelisting or static RBAC.
Infrastructure and agents cannot race each other to recover. Let one handle runtime goals; let the other enforce systemic safeguards.
Prep step: Clearly separate agent fallback scope (what they control) from infrastructure failover (what you own). Define negotiation rules and override conditions.
As AI matures from isolated models to autonomous agents, the enterprise faces a strategic inflection point. These agents will not operate in greenfield environments—they’ll integrate with existing applications, call legacy APIs, and drive decisions across critical business systems. That means enterprises must prepare now to support them, not just with new tools, but by rethinking how their architecture handles intent, execution, and governance.
This is not a rip-and-replace moment. It’s a convergence moment—where traditional systems and emerging agent behaviors must interoperate with precision and intent.
Agent architectures are coming. Enterprises that prepare for it now won’t just keep up, they’ll lead.
PUBLISHED JULY 01, 2025
