Scaling apps and APIs today is not about choosing the right load balancing algorithm. In the more than two decades of app delivery evolution, the one thing that’s remained fairly constant is load balancing algorithms. Their primary benefit is maintaining availability. Their impact on performance is, at best, minimal.
This is not to say that choosing an algorithm is irrelevant. After all, round robin is rarely the best choice for an API or application, but the choice between least connections and fastest response are less likely to have an impact on the overall performance and availability of a digital service than its architecture.
What this will be is an architectural perspective on app delivery in response to the elevation of app delivery as one of the six key capabilities required to design and operate digital services.
A load balancing algorithm is a programmatic approach to distributing load across a pool of resources to ensure availability and improve performance.
A load balancing algorithm specifies how specific resources are chosen and what variables are considered.
Round Robin is the simplest algorithm and simply iterates over a known set of resources in sequential order. If there are three resources – A,B, and C – then round robin routes the first request to A, the second to B, and the third to C. The selection process then begins again.
Least Connections is an algorithm based on the second operational axiom which states that ‘as load increases, performance decreases.’ Thus, the least connections algorithm will choose the resource with the least connections (load). Variations of this algorithm exist, most notably weighted least connections, which allows for differences in capacity across resources.
Fastest response time is used when performance is a top priority. The load balancer will, either passively or actively, determine the response time from each resource and, for every request, choose the fastest. This algorithm does not guarantee user response time as it has no effect on the last mile or user network conditions.
Source IP is an algorithm left over from network load balancing that uses a simple hash value for the source (client) IP to choose a resource. This algorithm will always select the same resource for a given source IP. This algorithm fell out of favor because it is subject to the ‘mega proxy’ problem, where all users originating from a single proxy/IP address are directed to the same resource. This tends to overwhelm the target resource, resulting in poor performance and, ultimately, failure.
Load balancing algorithms are an important part of an app delivery architecture but have less of an impact on the performance and scale of an app or digital service than the overall architectural approach.
App delivery is the discipline of designing a scalable, high performing architecture for apps, APIs, and digital services. It relies heavily on load balancing as a core component but incorporates modern capabilities such as layer 7 routing and leverages common architectural patterns to optimize performance and efficient utilization of resources.
We use the term app delivery to deliberately draw a line between load balancing, which is an implementation detail, and architecture, which is a design process.
Scale is technical response to a business outcome. Namely, the need to maintain availability and performance of the workloads that comprise a digital service to improve customer satisfaction scores, conversion rates, and generation of revenue. That last part is particularly important, as our research tells us that a majority (58%) of businesses today drive at least half their revenue from digital services.
Also consider, for example, the use of public cloud for business continuity (BC). BC is a top primary use of public cloud, and at its core is an implementation of global scale, i.e. global load balancing. Failover is a core capability of app delivery that, when applied to an entire site, enables the ability to rapidly redirect requests from one location to another. The continuous availability of a business’ digital presence is a business outcome, enabled by a technical response.
Answering this question begins our technical journey into app delivery architecture. There are two models of scale: vertical (up) and horizontal (out).
Vertical scale is based on the principle that adding more processing power to a system will increase capacity. This method of scale primarily benefits monolithic applications and systems that are self-contained. Aside from infrastructure, most organizations no longer rely on vertical scale because it requires changing the physical environment – adding CPUs or RAM or expanding network capacity. While vertical scale is made much faster by virtualization, especially in public cloud environments, the requirement to migrate software and systems – even to a new virtual machine – can be disruptive.
Horizontal scale is an architectural approach to adding more processing power by increasing the total available resources. This is achieved by distributing the processing power over multiple instances of an application, service, or system. This is the most common method of scale today as it relies on duplicating resources instead of migrating them. Furthermore, horizontal scale offers a greater variety of architectural options than vertical scale, making it better suited for all applications and APIs.
It should be no surprise that modern app delivery patterns, then, are based upon the principle of horizontal scale.
Simply choosing horizontal scale is not the end of the discussion.
Once the decision is made (generally it’s the default decision) additional considerations should drive an architectural decision regarding implementation. The simplest way to approach that decision is through the lens of the scale cube as described in the book, The Art of Scalability.
Very simply, there are three axes in the scale cube: x, y, and z. Each one maps to a load balancing architectural pattern. Each of those patterns is appropriate for meeting specific outcomes related to performance and availability given different types of applications and APIs.
A digital service is likely to use an architecture that incorporates multiple patterns to optimize performance and resource consumption at the same time. This approach requires systems thinking, as it must consider all the components, how they will interact, and how requests will flow from user to app and back.
The X-Axis pattern is the most basic pattern. It is based on horizontal duplication and the bulk of the work is accomplished via a load balancing algorithm. It is the simplest pattern and results in what I call Plain Old Load Balancing (POLB).
We call it this because of the simplicity of the architecture, which takes no advantage of advanced capabilities of modern load balancers to interact with requests and responses at the application layer.
In this pattern, applications are duplicated, and requests are forwarded to an instance based on the decision of the configured load balancing algorithm.
Because this pattern is often used in conjunction with TCP (layer 4), it has performance advantages over other patterns that rely on inspection of HTTP (layer 7). Mainly, connections can be stitched together rather than proxied, which effectively turns the load balancer into a network hop after the initial connection. This results in greater performance overall but eliminates the ability of the load balancer to inspect or act on requests and responses after the initial connection. Because X-axis architectures excel at ensuring availability and can be highly performant, they are often used to scale infrastructure and security services such as firewalls and application gateways.
A variety of traditional (monoliths, three-tier web, and client-server) applications tend be scaled using this pattern as it is rarely the case that these applications are decomposed into more discrete components that can be leveraged for modern app delivery architectures.
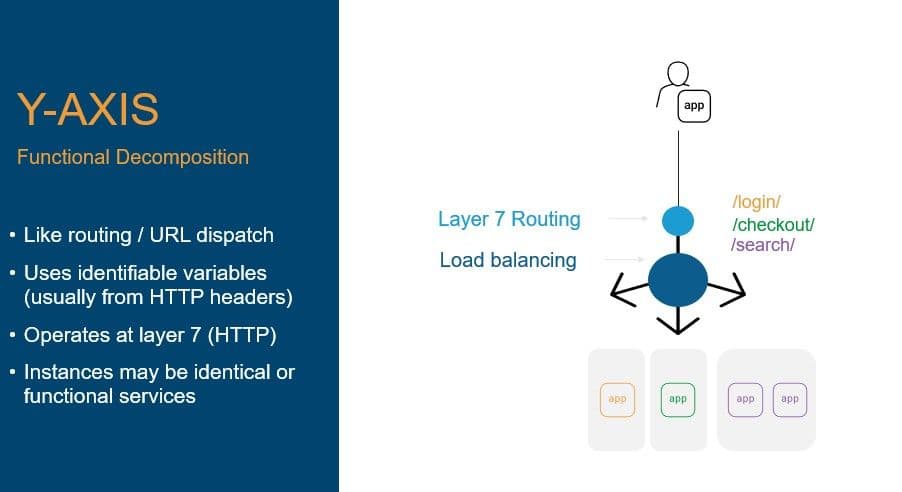
This pattern is based on functional decomposition and leverages the application layer (layer 7) capabilities of app delivery to scale based on functions rather than whole systems. The y-axis pattern is the first pattern in which layer 7 routing becomes a key tool in the app delivery architecture toolbox.
In general, y- and z-based patterns take advantage of layer 7 routing to choose a pool, and then a load balancing algorithm is used to select a specific resource. This diverges from the basic x-pattern, in which no layer 7 routing is used.
This pattern assumes operation at layer 7, typically HTTP, and uses some variable to distribute traffic to specific instances of an application or service. For example, if the pattern /login is found in the URI, then the load balancer will choose an instance, based on the configured load balancing algorithm, in a pool of app instances that only handle requests to login. The variable can be anything in the request header or the payload of the request. This allows for agent-based routing, API routing, and content-based routing (images, scripts, etc.).
Application instances may be clones. This is often the case when there is disparity in usage of an app that can be identified by a variable in the request. For example, login versus checkout functions may be discerned in a request based on the URI, a value in the HTTP header, or by a value in the request payload. Applying a y-axis pattern allows traditional applications to scale based on function, which results in greater efficiency of resource utilization because more resources can be allocated to handling high-volume functions while maintaining expected performance of other functions.
The use of the y-axis pattern to functionally scale traditional applications originated before the prevalence of microservices, which today functionally decompose applications. The y-axis pattern is still applicable to microservices and indeed the pattern is implemented by ingress controllers today. Astute readers will note that this pattern is applicable to APIs, as well, given they rely on HTTP (layer 7) constructs, making it no surprise that API gateways leverage this foundational pattern.
This pattern was made popular by eBay in the early days of Web 2.0. Its scalability architecture then included segmentation of functions into separate application pools. Selling functionality was served by one set of application servers, bidding by another, search by yet another. In total, they organized roughly 16,000 application servers into 220 different pools. This allowed them to scale each pool independently of one another, according to the demands and resource consumption of its function. It further allowed them to isolate and rationalize resource dependencies - the selling pool only needed to talk to a relatively small subset of backend resources, for example.
The y-axis pattern can also be used to distribute different types of content requests such as images to one pool of resources and other content types to others.
Using the y-axis to distribute load enables components of a digital service to scale individually, which is far more efficient in terms of resource utilization than an x-axis pattern. It allows for configuration optimization at the service or application layer that can improve its performance by adjusting specific variables in the web or app server to optimize for a given content type.
The Z-Axis pattern became popular out of sheer necessity with the explosive growth of social media and the Internet at large. It is, at its core, a Y-axis scaling pattern with additional segmentation applied, typically based on a specific variable like username or a device identifier.
This pattern allows for architectural differentiation using a technique derived from data sharding.
“A database shard, or simply a shard, is a horizontal partition of data in a database or search engine. Each shard is held on a separate database server instance, to spread load. Some data within a database remains present in all shards, but some appear only in a single shard.”
Wikipedia1
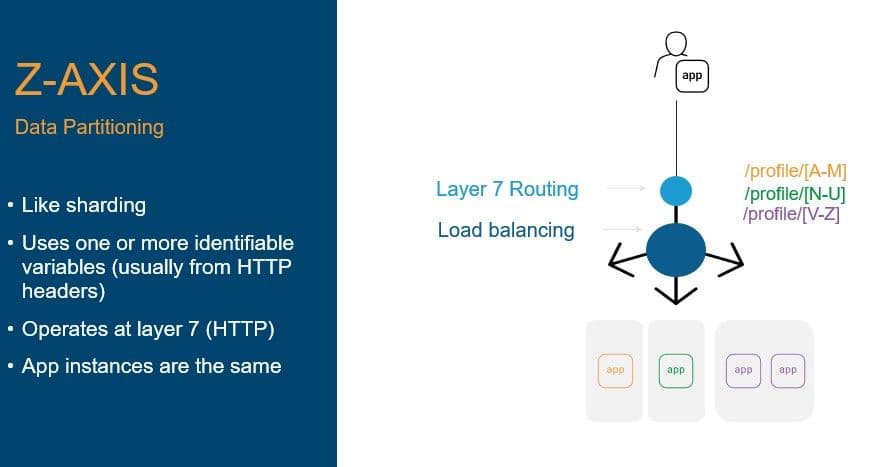
This pattern applies the principles used in databases to distribute requests based on some piece of data in the request. It can be used to assist in addressing bottlenecks in the data layer, as well as a means of ensuring compliance with data sovereignty rules. It uses an identifiable – and typically unique – variable to route requests across a horizontally scaled pool of resources. This pattern is generally used when high throughput is needed, such as significant volumes of requests for a specific service or application.
The Z-axis pattern is particularly useful for managing edge and IoT devices, which can number in the millions. By using device identifiers as the base pattern for sharding requests, the speed with which data can be transferred can be significantly improved. This can be particularly helpful for devices which store their configurations in a remote (cloud or data center) location, as this data is unique to the device and can be sharded safely.
This pattern tends to improve performance because data access at high load can significantly degrade performance. Thus, by splitting data access across more instances, load decreases and with it, performance improves. This requires careful attention to data integrity and may result in consistency issues when used to shard shared data. Meta elevated the topic of sharding when it developed service sharding as part of its overall architecture. Its careful attention to developing a highly performant and scalable app delivery architecture is an excellent example of how recognizing app delivery as a formal tier within a larger architecture can net significant benefits.
For services accessing non-primary data sources, a z-axis pattern can improve throughput without significantly impacting data quality across the system. This approach alleviates the need to add code to tie a specific instance of an application or API to a data source, relying instead on combination of the configuration of the data connectors at the instance level and app delivery routing to ensure the right data source is used.
It is rare today, in a world where digital services are delivered, to use just a single app delivery pattern to architect a high performing, reliable digital service. This is because of the inherent complexity of both digital services and the increasing diversity of ‘users’ – which can span devices, humans, and software.
Thus, an architectural approach considers the best of use of app delivery patterns across a digital service to deliver an optimal experience to users.
There is no ‘right’ or ‘wrong’ architectural solution because it is highly dependent on the services and applications that comprise a digital service, except that such a solution should not be based on load balancing algorithms alone.
Indeed, one should note there has been no mention of algorithm selection, as the choice of how load is distributed within a load balancing pattern is not as relevant as making the right architectural choice for a specific app or API.
This is one of the factors driving app delivery as a discipline. The way in which app delivery and security is used and implemented today goes far beyond the simple scale of a web server. Its implementation can impact performance, availability, and ultimately make or break business outcomes. Thus, it is important for organizations to approach app delivery as a strategic, architectural tool in their design toolbox.
Load balancing remains the core technical requirement for scale. Understanding app delivery patterns and how they leverage load balancing will provide a better perspective on architecting for scale and performance of digital services, especially when those services are likely to be hybrid and comprise a mix of APIs and both modern and traditional apps.
FOOTNOTE
