
It has been said that the IT budget is where strategy lives or dies. If that’s the case, then AI strategies are alive and well.
Our most recent research indicates organizations are allocating, on average, 18% of the IT budget just for AI. But it’s how that 18% is being allocated that gives us a glimpse into their strategies for AI.
About 18% of the AI budget today is going toward AI services; third-party applications that integrate or offer some kind of AI tooling. The rest goes toward models (19%), development (16%), security (9%), data technologies (11%), and GPUs (9%).
Combined with the equal split of spending between training (50%) and inferencing (50%) and the finding that AI will be distributed across public cloud (80%) and on premises (54%), one can surmise that organizations are planning for significant change in their infrastructure to support the full AI life cycle.
Part of that support requires a fresh look at the network.
Building out the infrastructure to support both training and inferencing requires careful attention to modern application environments, e.g., Kubernetes, and how traffic will flow across AI instances and between models and the applications that use them.
While NVIDIA is not the only provider of acceleration technology (GPUs, DPUs, IPUs, etc.) they are leading the way when it comes to reference architecture. It is in those details that we find significant impacts on networking and scalability architecture.
AI Pods, Clusters, and Factories
There is considerable angst in the industry right now about the use of terminology specific to Kubernetes. Whereas operators have come to understand the definition of pods and clusters, leading GPU providers are fudging those definitions when it comes to deploying inferencing at scale.
For example, NVIDIA refers to AI pods, which are Kubernetes clusters. And they call a related set of clusters an AI factory.
I’m not here to argue terminology—I rarely win those arguments—so instead I’m focusing on these units of AI capabilities and what they mean to the network.
One of the realities of scaling generative AI, in particular, is the demand for compute cycles. Specifically, GPU compute cycles. To accommodate this demand, especially for providers of AI services, it is necessary to build out complex AI compute units. These units are what NVIDIA calls AI pods, but others will no doubt have their own especial names for them. They are essentially Kubernetes clusters.
That means a lot of E-W traffic internal to the AI compute unit, but it also means a lot of N-S traffic into those AI compute units. And that’s where we find ourselves looking at a significant change at the boundary between traditional data center infrastructure and emerging AI compute complexes.
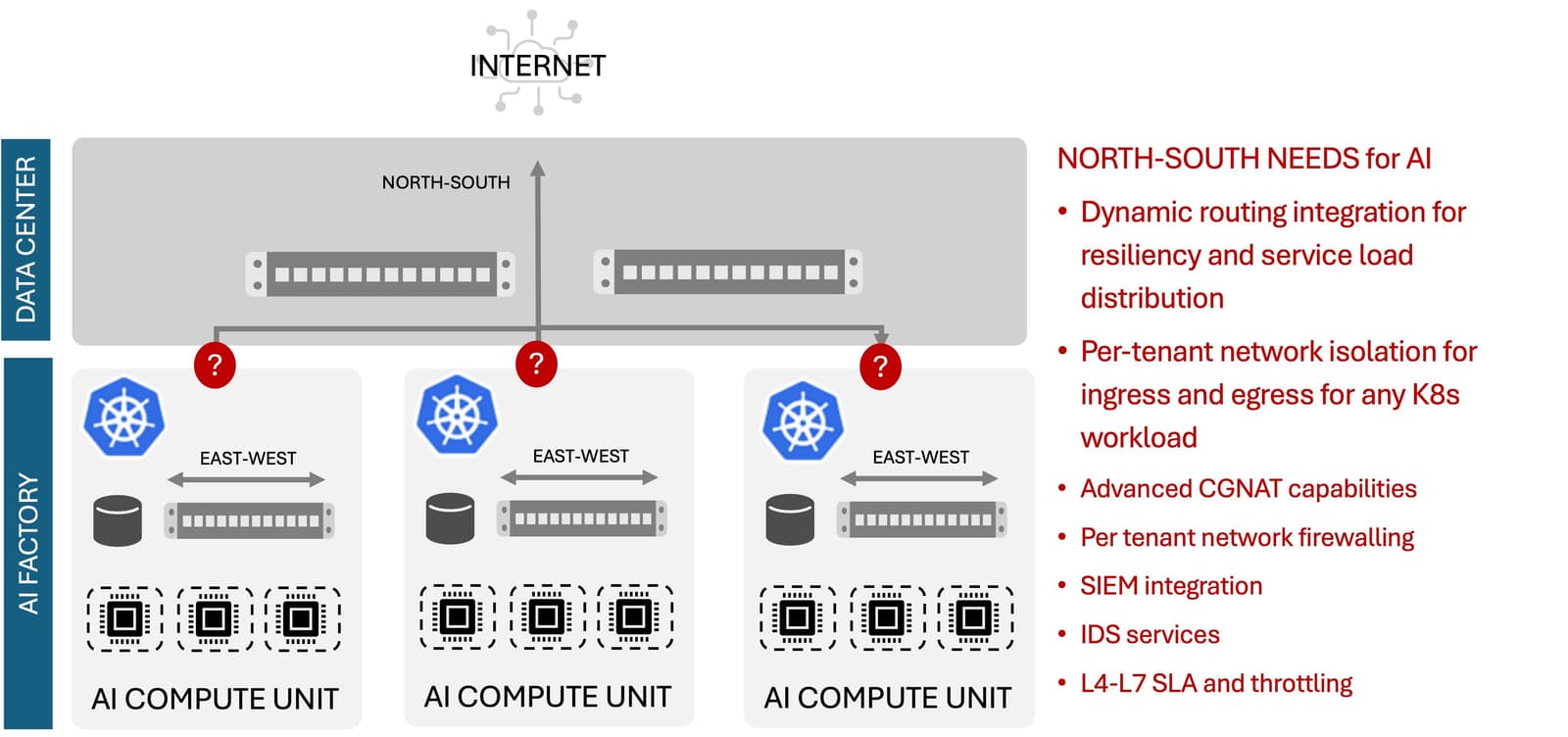
There’s a lot going on at that boundary, especially for service providers who need per-tenant network isolation. There’s also considerable need for L4-7 traffic management, including rate throttling so as not to overwhelm AI resources. There’s also the expected load balancing for scale and distribution, as well as network services like advanced CGNAT capabilities.
Much of this is needed by enterprises, too, who hope to scale out their AI implementations to support an expanding set of business use cases from productivity to code and content generation to workflow automation and, of course, the growing interest in using AI for operations. While per-tenant isolation may not be an enterprise requirement, it can be helpful for ensuring that high-priority AI workloads—like automation and operational analytics—are not suffocated by lower-priority AI workloads.
Whether service provider or enterprise, the data center is going to undergo significant changes in the network. Inserting AI workloads into what is a traditional data center architecture may lead to failure to scale or even operate reliably.
Understanding the changes to the data center architecture is important as is having tools and technologies like BIG-IP Next SPK available to deliver the capabilities needed to successfully modernize the data center network to support every AI workload and the business that will ultimately rely on them.
About the Author

Related Blog Posts

Multicloud chaos ends at the Equinix Edge with F5 Distributed Cloud CE
Simplify multicloud security with Equinix and F5 Distributed Cloud CE. Centralize your perimeter, reduce costs, and enhance performance with edge-driven WAAP.

At the Intersection of Operational Data and Generative AI
Help your organization understand the impact of generative AI (GenAI) on its operational data practices, and learn how to better align GenAI technology adoption timelines with existing budgets, practices, and cultures.
Using AI for IT Automation Security
Learn how artificial intelligence and machine learning aid in mitigating cybersecurity threats to your IT automation processes.
Most Exciting Tech Trend in 2022: IT/OT Convergence
The line between operation and digital systems continues to blur as homes and businesses increase their reliance on connected devices, accelerating the convergence of IT and OT. While this trend of integration brings excitement, it also presents its own challenges and concerns to be considered.
Adaptive Applications are Data-Driven
There's a big difference between knowing something's wrong and knowing what to do about it. Only after monitoring the right elements can we discern the health of a user experience, deriving from the analysis of those measurements the relationships and patterns that can be inferred. Ultimately, the automation that will give rise to truly adaptive applications is based on measurements and our understanding of them.
Inserting App Services into Shifting App Architectures
Application architectures have evolved several times since the early days of computing, and it is no longer optimal to rely solely on a single, known data path to insert application services. Furthermore, because many of the emerging data paths are not as suitable for a proxy-based platform, we must look to the other potential points of insertion possible to scale and secure modern applications.