
In today's rapidly evolving technology landscape, the deployment and operationalization of AI have become crucial differentiators for enterprises. As enterprises harness the power of AI for enhanced decision-making and efficiency or develop differentiating products with AI, AI factories have emerged as a foundational model. At the heart of AI factories lies Retrieval-Augmented Generation (RAG), one of the seven AI building blocks and the one that enables AI outputs to be contextually aware, more accurate, and timely.
Earlier in our AI factory series, we defined an AI factory as a massive storage, networking, and computing investment serving high-volume, high-performance training and inference requirements. In this article, we will discuss two of the AI building blocks we defined: RAG and RAG Corpus Management.
Understanding the AI factory
Like a traditional manufacturing plant, an AI factory is designed to build AI outputs and models through a meticulously orchestrated infrastructure of servers, GPUs, DPUs, and storage. Supporting training and inferencing, AI factories are crucial for developing AI applications at scale. However, incorporating RAG to enhance the contextual relevance of its outputs unlocks the true potential of an AI factory.
What is Retrieval-Augmented Generation, aka RAG?
Before we dive in, let's define Retrieval-Augmented Generation: RAG is an AI technique that incorporates proprietary data to complement AI models and deliver contextually aware AI outputs. As application deployments are becoming more distributed, hosted across hybrid and multicloud environments, an enterprise's data is everywhere. The question arises for organizations that want to unlock the strategic advantage of their data for AI: how do we connect relevant data to augment inputs into AI models like large language models (LLMs)? Organizations are turning to RAG to solve this and create secure highways from the AI model to the distributed data silos. This allows access to the latest information, making outputs timely, contextually aware, and more accurate. Without this, even fine-tuned AI models don't have access to the latest information, which frequently changes as soon as the training is complete.
“RAG is an AI technique that incorporates proprietary data to complement AI models and deliver contextually aware AI outputs.”
What are some examples? Two to consider are vision-based self-driving vehicles, and LLMs when they hallucinate or make assumptions from a request’s lack of contextual relevance.
For self-driving vehicles, inferencing must include real-time data based on the vehicle's location and the ever-changing environment around it to safely navigate streets with pedestrians, cyclists, and other automobiles. For LLMs, and using a customer support chatbot example, access to product information like change logs, knowledge bases, system status, and telemetry paired with unique customer information like support tickets, purchase history, and customer profiles transform generic LLM responses into valuable outputs.
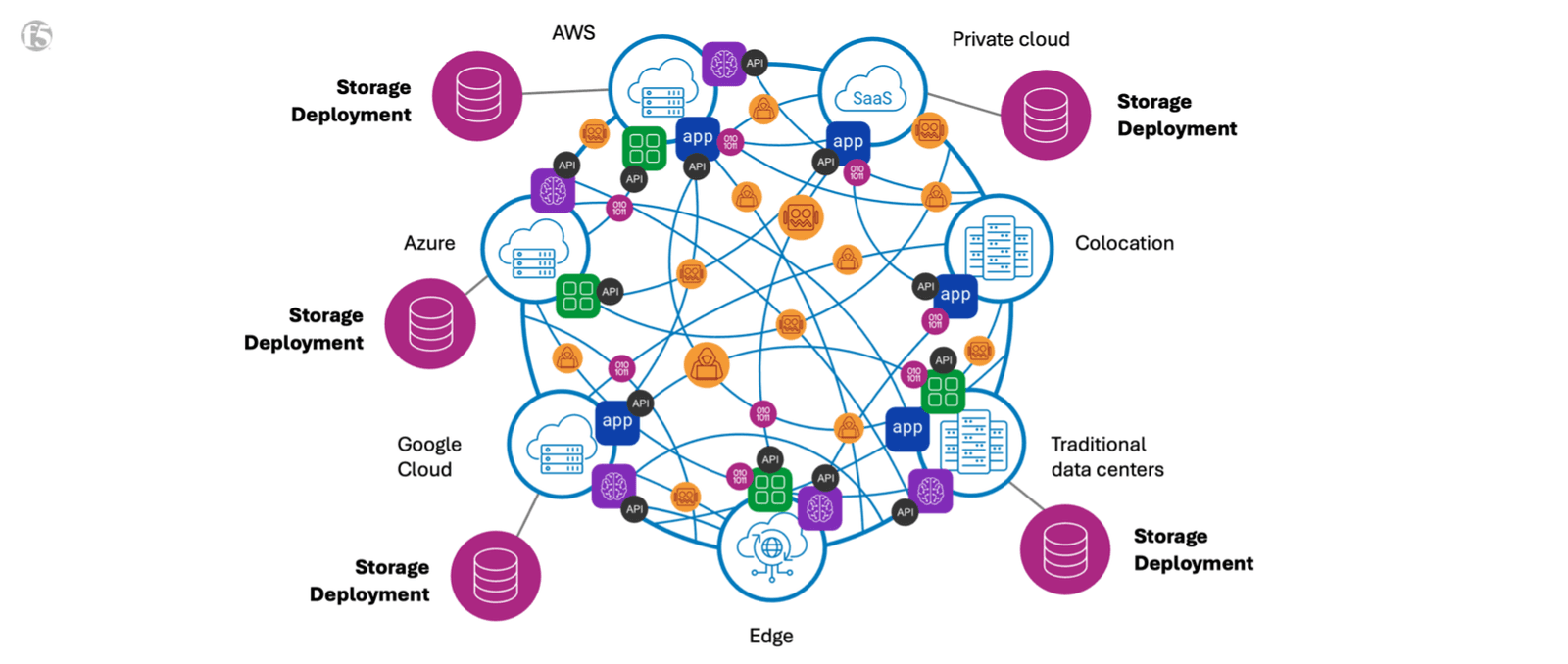
Hybrid and multicloud environments are becoming increasingly complex and storage deployments are increasingly siloed in disparate locations. At F5, we call this phenomenon the “ball of fire.”
RAG for AI factories
RAG in the context of AI factories elevates the basic inference capabilities of foundational AI models by pulling additional context from vector databases and content repositories, which are then utilized to generate context-enriched responses. Within an AI factory, the orchestration layer in RAG manages complex interactions between the AI model and augmentation services, ensuring seamless integration of supplemental data into AI workflows.
For example, in the customer support scenario mentioned above, RAG can access and incorporate data from various relevant databases and sources. This results in AI outputs that are highly relevant. By integrating RAG into the AI factory framework, enterprises can enhance the quality and timeliness of their inference responses, thereby driving more effective decision-making and operational efficiency.
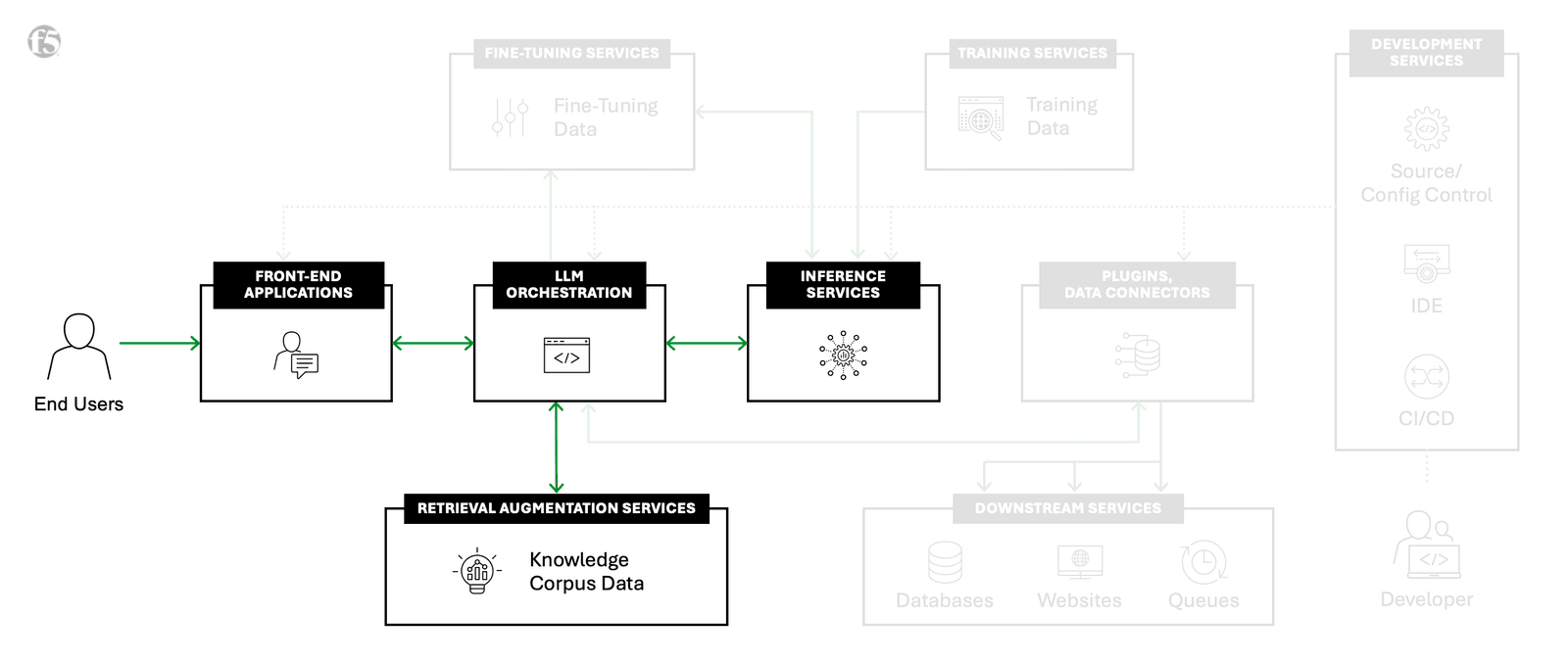
F5’s AI Reference Architecture highlighting RAG, one of seven AI building blocks needed for successful large-scale AI infrastructures.
RAG Corpus Management for AI factories
RAG Corpus Management focuses on the data ingestion and pre-processing essential for delivering inference with RAG. This involves a series of steps, including data normalization, tokenization, embedding, and populating vector databases, to ensure the content is optimally prepared for RAG calls.
Within an AI factory, this process starts with normalizing various data formats to create a consistent and structured dataset. Next, embeddings are generated to convert this data into a format that AI models can query. The prepared data is inserted into vector databases, knowledge graphs, and content repositories, making it readily accessible for real-time retrieval during inference. By ensuring data is clean, structured, and retrievable, RAG Corpus Management enhances the overall effectiveness and precision of the AI outputs. This process is vital for enterprises aiming to maintain high-quality, contextually enriched AI responses.
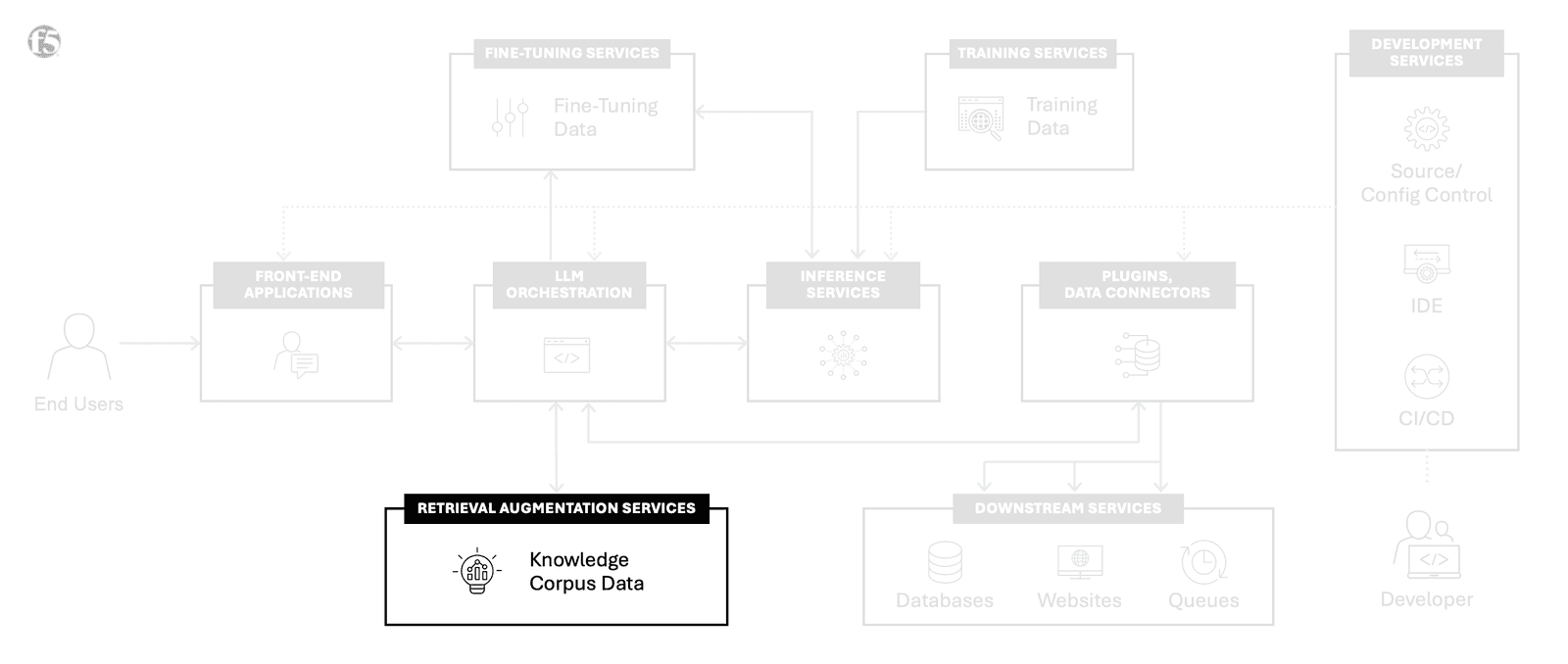
RAG Corpus Management is one of seven AI building blocks F5 has defined for a successful AI architecture.
Is RAG only applicable to AI factories?
While RAG is a core building block for AI factories, it's needed for all sizes of AI model deployments. Given foundational AI models (e.g., GPT, Llama) are trained on public information, deploying a foundational model does not provide organizations with a high enough competitive advantage over other organizations deploying the same model. Integrating proprietary and non-public data via RAG is essential for any organization, with any AI deployment size, to complement requests with their data. An example would align with the customer support chatbot and the requirement of an LLM-powered support app having access to product- and customer-specific information to deliver a useful solution. Even with training or fine-tuning models, access to ever-changing data is required for more accurate outputs.
Creating secure data highways for RAG enablement
As organizations continue to invest in AI to drive innovation and operational efficiency, the importance of RAG within AI factories cannot be overstated. By enhancing contextual awareness, accuracy, and timeliness, RAG ensures AI models deliver outputs that are both more relevant and reliable. For enterprises looking to create secure integrations between their data silos and AI factories, F5 Distributed Cloud Network Connect provides modern-day highways—securely connecting proprietary corporate data locations, providing restricted access, simplifying networking, and delivering data storage and mobility across zones and regions.
F5’s focus on AI doesn’t stop here—explore how F5 secures and delivers AI apps everywhere.
Interested in learning more about AI factories? Explore others within our AI factory blog series:
- What is an AI Factory? ›
- Optimize Traffic Management for AI Factory Data Ingest ›
- Optimally Connecting Edge Data Sources to AI Factories ›
- Multicloud Scalability and Flexibility Support AI Factories ›
- The Power and Meaning of the NVIDIA BlueField DPU for AI Factories ›
- API Protection for AI Factories: The First Step to AI Security ›
- The Importance of Network Segmentation for AI Factories ›
- AI Factories Produce the Most Modern of Modern Apps: AI Apps ›
About the Author

Related Blog Posts

Why sub-optimal application delivery architecture costs more than you think
Discover the hidden performance, security, and operational costs of sub‑optimal application delivery—and how modern architectures address them.

Keyfactor + F5: Integrating digital trust in the F5 platform
By integrating digital trust solutions into F5 ADSP, Keyfactor and F5 redefine how organizations protect and deliver digital services at enterprise scale.

Architecting for AI: Secure, scalable, multicloud
Operationalize AI-era multicloud with F5 and Equinix. Explore scalable solutions for secure data flows, uniform policies, and governance across dynamic cloud environments.

Nutanix and F5 expand successful partnership to Kubernetes
Nutanix and F5 have a shared vision of simplifying IT management. The two are joining forces for a Kubernetes service that is backed by F5 NGINX Plus.

AppViewX + F5: Automating and orchestrating app delivery
As an F5 ADSP Select partner, AppViewX works with F5 to deliver a centralized orchestration solution to manage app services across distributed environments.

F5 NGINX Gateway Fabric is a certified solution for Red Hat OpenShift
F5 collaborates with Red Hat to deliver a solution that combines the high-performance app delivery of F5 NGINX with Red Hat OpenShift’s enterprise Kubernetes capabilities.