Introduction
In today's digital landscape, the proliferation of scraper bots poses a significant threat to organizations of all sizes. These automated tools, designed to extract data from websites and APIs for various purposes, can lead to severe consequences if not properly managed. It’s important to understand the potential threats posed by scraper bots, which range from intellectual property theft and competitive advantage erosion to website/API performance degradation and legal liabilities. By remaining vigilant and implementing robust measures, businesses can mitigate these risks and safeguard their valuable data assets.
Scraping is one of the OWASP top 10 automated threats: OWASP OAT-011. OWASP defines scraping as the use of automation to “collect application content and/or other data for use elsewhere.” This is one of the largest sources of unwanted automation against web, mobile and API applications. Scraping comes in many different varieties and is driven by a number of factors. It impacts businesses across a variety of industries and its legal status varies depending on geographic and legal jurisdictions.
This article offers a comprehensive view of the scraping landscape. It defines what scraping is, how it is done, its legality, and the difference between scraping and other forms of web crawling. It further describes the differences between web and API scraping, the motivations and business models of scrapers as well as the direct and indirect costs imposed on businesses by scraper bots. Future articles in this series will evaluate different ways to detect and mitigate scrapers, how scrapers evade attempts at detection and mitigation, as well as provide case study overviews of scrapers that F5 Labs has encountered across different industries.
What Is Scraping?
Scraping is the process of using automation to extract large amounts of data and content from a website or API. Scraping websites is referred to as web scraping and involves requesting web pages, loading them, and parsing the HTML to extract the desired data and content. On the backend, this data is then aggregated and stored in a format best suited to the scraper’s desired use. Examples of things that are heavily scraped on the internet are flights, hotel rooms, retail product prices, insurance rates, credit and mortgage interest rates, contact lists, store locations, and user profiles.
Why Use Automation?
Scrapers try to extract large amounts of data and content from target websites and APIs. This amount of data and content is usually beyond the volume that data and content owners intend to provide. Otherwise, they would have offered a download feature. As a result, scrapers use automation to generate large numbers of smaller requests and aggregate the resulting data piece by piece, until they have all the data or content needed. This typically involves tens of thousands or even millions of individual requests.
To counteract this possibility, most data or content owners impose request rate limits on their platforms to restrict how much data a single user can access. Scrapers seeking to circumvent such request thresholds design requests that seem unrelated, as if they were coming from different users, as a way to avoid these controls.
Prevalence of Scraping
In the 2024 Bad Bots Review by F5 Labs, we analyzed the prevalence of automated attacks against different endpoints on web and mobile APIs. This analysis, summarized in Figure 1 below, showed that scraping bots were responsible for high levels of automation on two of the three most targeted flows, Search and Quotes, throughout 2023 across the entire F5 Bot Defense network.
According to the research, 20.1% of all web search and 11.0% of all mobile search requests were made by scrapers. Rate-quote flows for insurance and other business websites experienced 15.1% automation from web scrapers trying to collect the data required to reverse engineer insurance rate tables or to power insurance quote comparison services. Despite these scrapers being blocked from accessing the required content or data due to anti-bot defenses in place, they still launched large volumes of scraping attempts.
The scraping rates for enterprises in the wild that do not block scrapers using advanced solutions is significantly higher. Absent any advanced bot defense solution, upwards of 70% of all search traffic originates from scrapers. This percentage is based on numerous proof of concept analyses done for enterprises with no advanced bot controls in place.
Scraper Versus Crawler or Spider
A scraper differs from a crawler or spider. The former is primarily designed to extract data and content from a website or API, while the latter is primarily focused on indexing and mapping out a given website or API. This means crawlers and spiders are focused on “knowing” the organization of a website or API. Crawlers and spiders are used to index websites for search engines by cataloging what content or data exists on a site. This enables the search engine’s users to find the content or data they seek, even though the crawlers do not extract a copy of that data.
Scrapers, on the other hand, are designed to extract and exfiltrate the data and content from the website or API. The data and content can then be reused, resold and otherwise repurposed as the scraper intends.
Is Scraping Legal?
Scraping is typically in violation of the terms and conditions of most websites and APIs. The question of its legality is a challenging one and best answered by legal experts. In a famous case brought by LinkedIn in 2017 against hiQ Labs,1 which was scraping LinkedIn profiles and data, the court initially ruled in 2019 that LinkedIn could not prevent hiQ Labs from accessing publicly available user profile data. Essentially, the court stated hiQ had the right to scrape LinkedIn data. This decision was then later overturned by the Supreme Court in June 2021 and sent back to the lower courts to be re-litigated. Finally in November 2022, the U.S. District Court for the Northern District of California ruled that hiQ had breached LinkedIn's user agreement and a settlement was reached between the two parties.
Scraping: Web vs. API
Most scrapers target information on the web, although scraping activity against APIs is on the rise. For information found on a website, the content is usually embedded in some form of HTML. It has to be parsed out before it can be reformatted, aggregated and stored into another format. Information obtained from APIs is usually formatted in a way that negates the need to parse and reformat the data before it can be aggregated and stored. This makes scraping of APIs a more attractive proposition from a data formatting standpoint. APIs frequently have better controls for using API keys and rate limiting, which can make scraping more difficult. However, not all APIs have such controls in place.
Business Models for Scraping
There are many different parties active in the scraping business, with different business models and incentives for scraping content and data. Figure 2 below provides an overview of the various sources of scraping activity.
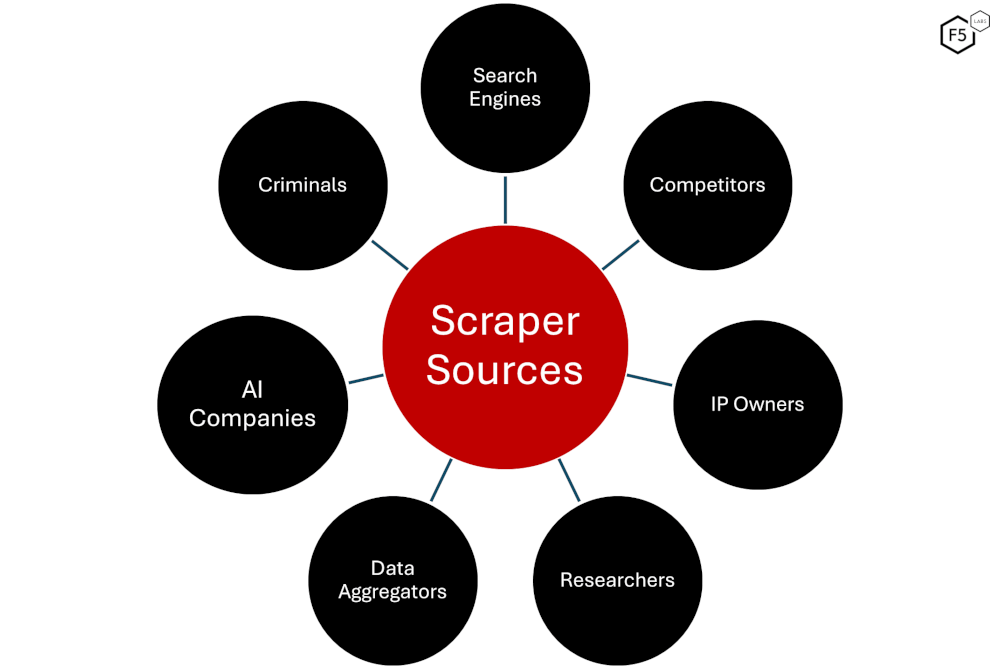
Figure 2: Sources of scraping.
Search Engine Companies
These are typically crawlers or spiders belonging to large search engine providers. They index content from websites all over the internet so they can help users of their search engines to find things on the internet. Google, Bing, Facebook, Amazon, Baidu, etc. all have scrapers that regularly visit every single website on the public internet. The business model for these scrapers is selling ads that are placed alongside search results. The search ad business pays for the scraping activity.
Business Competitors
In many industries, competitors will constantly scrape content and data from each other. This practice takes a number of forms. The business model for competitors is to win customers, market share and revenue by using the information that they scrape from competitors to their advantage.
Competitive Pricing
This involves scraping pricing and availability of competitor products and undercutting competitor prices to win increased market share. In other instances, like airline tickets, knowing that competitors are sold out for a particular route will allow an airline to increase prices and maximize revenue.
Network Scraping
This involves scraping the names, addresses and contact details of a company’s network partners. This is common in the insurance space, where details of repair shops, doctors, hospitals and clinics, insurance agents and brokers are scraped. This can be done by competitors looking to identify gaps in the market or poach partners from competitors. It is also done by other third parties, for example, pharmaceutical companies whose representatives want to pitch new drugs to doctors in a particular region and specialty. Scraping health insurer websites for in-network doctors is an easy way to get this data.
Inventory Scraping
This involves stealing valuable content and data from a competing site for use on your own site. This typically includes things such as product imagery, descriptions, specifications, prices, and reviews. These can be stolen from one website and used on a competing website selling the same items. In one extreme case, we have seen a start-up classified ad company going to the website of the incumbent market leader and scraping entire categories of listings to populate their own website. Scrapers can also collect product reviews from one website to use to populate reviews on a different site.
Researchers and Investment Firms
Academics researching a given topic often design scrapers to go out onto the internet to gather content and data for their research. These academics are motivated by getting the data needed to complete their research and get it published. They usually have research funding they use to pay for their scraping activities.
We have also observed the activities of hedge funds and other investment firms using web scraping as a means to estimate the revenues and profitability of companies in various sectors. For example, by scraping flight prices, availability and seat maps, an investment firm can determine how full flights are going to be and the average prices that passengers are paying for those tickets. This allows them to estimate what revenues they expect the airline to bring in, and hence, buy or short the airline’s stock.
Market research firms also fall into this category. They use web scraping for research purposes and generate revenue by publishing and selling the results of their market research.
Intellectual Property Owners
We have observed scraping from organizations that use scrapers to scour the internet in search of counterfeit goods for sale in order to identify possible trademark or copyright infringements. Brand owners also use scraping to ensure that distribution partners and resellers are following pricing and discounting guidelines, as well as other contractual stipulations like use of correct imagery, placement, product descriptions, and branding. Scrapers allow these brands to ensure compliance with their requirements, while enabling them to identify counterfeit goods.
Data Aggregators
These are third parties who collect and aggregate data from many different sources and then sell the data to interested parties. Some data aggregators specialize in particular kinds of data or data for specific industries. An example is companies which specialize in scraping LinkedIn data and selling the names and contact information of executives and business leaders to sales and marketing people who want to target these individuals. Their business model is to simply sell the aggregated data.
Other examples of data aggregators include price comparison websites and apps which are very common in the retail, airline, car rental, hospitality, and insurance spaces. These price comparison services scrape prices and insurance quotes from various providers and give users the ability to compare and contrast offerings all in one place. These price comparison services generate revenue via referral commissions for business they drive towards a particular provider, or by charging a service fee or selling ads on their websites and apps.
Other Kinds of Data Aggregators
News aggregators also fall into this data aggregator category. These entities use scrapers to pull news feeds, blogs, articles, and press releases from many different websites and APIs. This includes public/private company websites, public relations firms, government and government agency websites, non-profit agencies, and more. The news is aggregated and published on their websites, apps, newsletters, or social media pages, or sold to other news agencies.
A more subtle example of a data aggregator is the Wayback Machine. This organization keeps a historical archive of the top sites on the internet so users can see what content was on those sites on specific dates in the past. They do this by scraping the content of the website, archiving it, and making it available to their users. The Wayback Machine is a non-profit organization and does not have a profit motive for their scraping activities.
Artificial Intelligence (AI) Companies
Since the launch of Open AI's ChatGPT, VC funding of generative AI startups has exploded, fueling additional scraping activity by AI companies. These companies need large amounts of text, image, and video data to train their models. They obtain this data by scraping content from the internet. Facial recognition startups like ClearView AI[1] have made headlines in the past for scraping billions of user photographs from the internet,[2] including the most popular social media sites. They used this scraped data to create an AI system that can put a name to a person’s photo within seconds. The resulting AI models are then sold to governments and law enforcement agencies.
We commonly see AI companies scraping all kinds of data across a variety of different industries. Sometimes these companies identify themselves, but often they do not. As the AI space continues to grow, we expect this to be an increasing source of scraping traffic.
Criminal Organizations
There are a number of malicious reasons why criminals might want to scrape a given website or application.
Phishing
Criminals scrape website content, layout, and data so that they can create replicas of the site or app to use for phishing. They register domains that are very similar to the victim domain and apply the scraped layout, content, and data to create a convincing phishing website. Users are then asked to hand over personally identifiable information (PII), including usernames, passwords, and MFA codes.
Vulnerability Scanning
Criminals use scrapers to test for and identify vulnerabilities in a website or application that can be exploited. For example, by changing the input into an insurance quote, hotel room reservation, or airline flight search application, attackers may find vulnerabilities that allow them to get discounted rates or access to back-end systems. Web scrapers are designed to supply millions of variations of inputs into applications and capture the resulting millions of outputs. This makes them ideal for vulnerability scanning.
Identity Theft
By scraping information, including PII, from social media and other sites, criminals can gather all the information they need to steal identities and enable fraud schemes such as spear phishing, social engineering, and account take over. This scraping also might provide answers to commonly used security questions and PIN numbers based on common choices such as a child’s birthday, which can then be used for credit card fraud.
Direct Costs of Scraping
There are several direct costs of scraping to the victims, leading to an impact to an organization’s bottom line.
Infrastructure Costs
Scrapers are typically very high volume and we commonly observe more than 50% of all traffic to scraped websites originating from scrapers. This means that more than half of the operating costs of the website are going towards servicing requests from scrapers.
Server Performance and Outages
Scraper transaction request volumes tend to be high and may use computationally intensive search features. Together, this can cause scrapers to pull so much compute resources that they cause the origin servers to fail, leading to an outage and effective denial of service on the website. These outages can cost a company substantial lost revenue, as legitimate customers cannot conduct transactions due to site outages or slowness.
Loss of Revenue and Market Share
Scraping activities driven by competitors result in loss of competitive advantage, and thereby lost sales revenue and market share. This loss of revenue and market share can also be a result of scraper-driven intermediation.
Intermediation
This occurs when a third party becomes an intermediary between a business and its customers. A significant proportion of scraping is done by intermediaries across many different sectors, including insurance, airlines, hotels, retail and government. The scraping is what provides these intermediaries with the data needed to intermediate the service providers, potentially leading to reduced revenue, profits, market share and customer dissatisfaction. Companies prefer to have direct relationships with their customers for a number of good reasons:
Selling and Marketing
By having a direct relationship with the customer, companies can send marketing emails and special offers directly and generate additional sales that would not happen if the customer’s relationship was with the intermediary.
Customer Retention
An intermediary can move customers from one provider to another depending on various incentives and this can lead to the loss of business revenue. Having a direct relationship allows companies to retain more of their customers.
Cross Selling, Up Selling
By having direct relationships with the customers, business can cross-sell and upsell additional products and services to the users, increasing revenue and profitability. For example, an airline can sell trip insurance, car rentals and hotel rooms to a customer. However, if the customer uses an intermediary, the airline will only sell the airline ticket, while the intermediary can provide additional services from other providers or from themselves, removing the airline’s opportunity to generate additional revenue.
Customer Experience
Having a direct relationship with customers allows companies to ensure the end-to-end customer experience. When intermediaries are involved, the service provider loses control of the experience, which can lead to dissatisfied customers. For example, in the airline industry, an intermediary may book connections that are too tight, or where bags do not automatically transfer. This may result in bad experiences and customers blaming the airline, tarnishing their reputation online when the fault lies with the intermediary. Companies therefore prefer to manage the entire experience by having direct relationships with their customers.
Indirect Costs of Scraping
Victims of scraping also experience costs that do not immediately affect their profits, but instead represent a loss of investment, harm to elements of a business that are difficult to quantify, or introduce other risks.
Loss of Intellectual Property
This can include proprietary pricing algorithms, data and statistics, product and user reviews and ratings. These take years and resources to develop, but can be stolen in a few hours by determined scrapers.
Reputational Damage
Users whose information is scraped may blame the website for sharing their information or even accuse them of selling their data to third parties, which can lead to brand damage.
Legal Liability
In the event that scraped data is later used in a way that causes direct harm to the data subject (the owner of the PII or other data), this may expose the scraped organization to potential legal liability for violation of user privacy if it turns out they did not take reasonable steps to prevent the scraping of this data by unauthorized third parties.
Questionable Practices
Sometimes scraped data can be used to discover and publicize discriminatory data models and business practices that can leave businesses in legal and reputational trouble. For example, researchers who scraped retailer prices for select products were able to identify instances of price collusion.
Conclusion
Scraping is a big deal and affects enterprises all over the world in many different industries. F5 Labs’ research across the enterprises from which we have data shows that almost 1 in 5 search and quote transactions are generated by scrapers. Scraping is usually done by various entities including search engines, competitors, AI companies, and benign or malicious third parties. Scraping leads to several direct and indirect costs for victim organizations, ultimately resulting in the loss of revenue, profits, market share and customer satisfaction.


