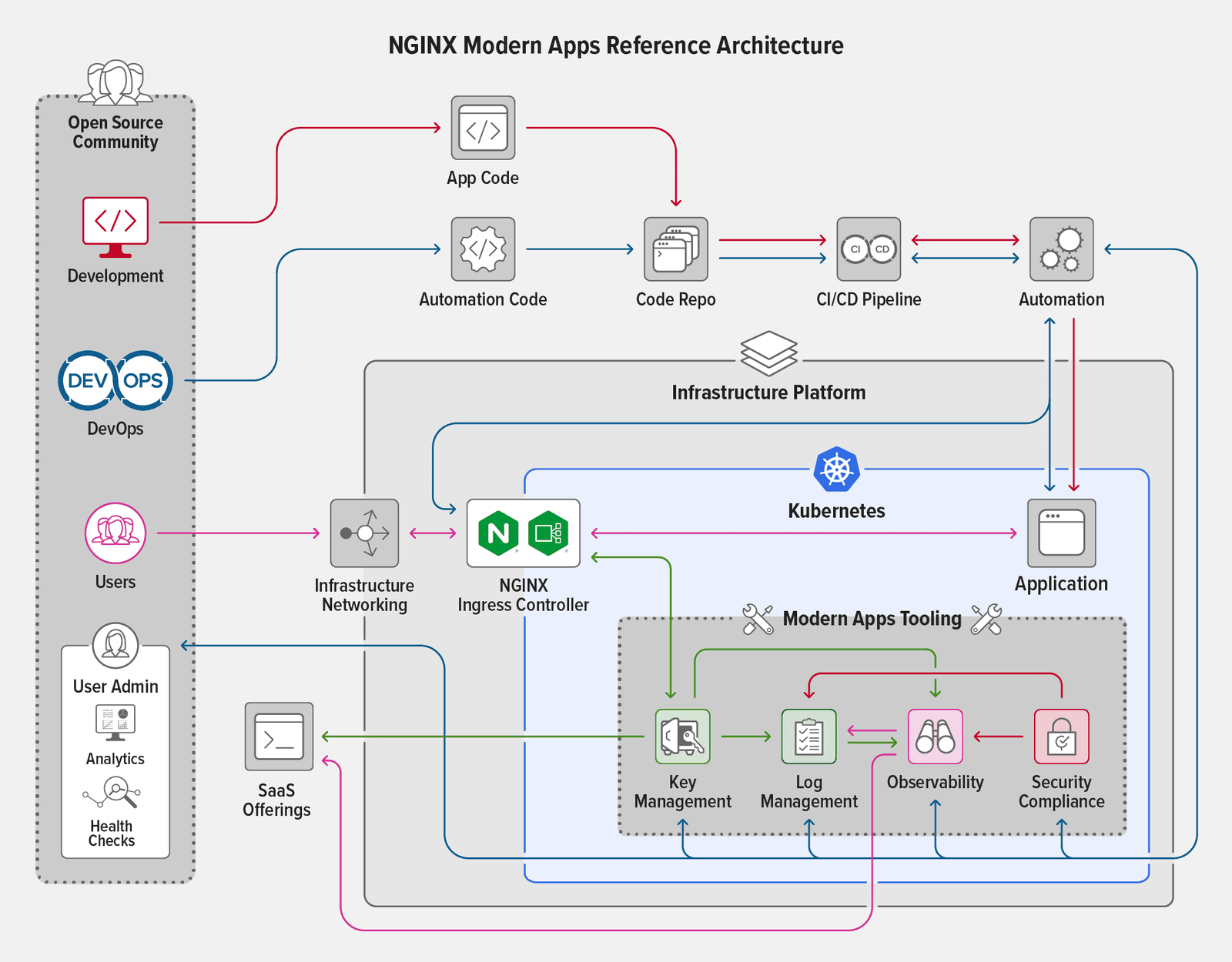
We were upfront with our design goals when we unveiled the NGINX Modern Applications Reference Architecture (MARA) at Sprint 2.0 in August of 2021. We wanted to create an example of a modern application architecture running in Kubernetes and designed to support security, scalability, reliability, monitoring, and introspection. This project needed to be deployable across different infrastructures with a “plug and play” approach to combining functional components without time‑consuming integration efforts.
In the months since Sprint, we have been moving forward with our roadmap. Like any project, we have had our share of success and failure and have worked our successes into MARA while keeping a growing list of lessons learned. We hope that we may keep others from hitting the same problems by documenting these issues and designing with these lessons in mind.
We have recently reached a milestone with MARA version 1.0.0, which reorganizes the project directory and changes the process for instantiating and destroying the environment. We eliminated duplicated code, created a directory structure that easily accommodates future additions, and standardized management scripts. As this version marks an important point in the history of MARA, we wanted to stop and report back to the community on our progress, note what we feel are some of the more important lessons learned, and provide some information on our roadmap moving forward.
Telemetry – Metrics, Logging, and Tracing
The core contributors to MARA have experience running software at scale and understand what it takes to deliver services from operational, engineering, and management perspectives. They know the sinking feeling you get when an application misbehaves and you don’t have an easy way to determine exactly what the problem is. A quote circulating around the DevOps world sums up the issue succinctly: “Debugging microservices is like solving a series of murder mysteries”.
With this in mind, we made the addition of observability a top priority on our short‑term roadmap. Observability in this context includes log management, metrics, and tracing data. Just collecting data is not sufficient, however – you must be able to dig into the data and make meaningful decisions about what is happening in the environment.
Our exploration of options for tracing led us to OpenTelemetry (OTEL) because it supports the entire span of telemetry data, logs, metrics, and traces. We envisioned an implementation where the OTEL agent collects, processes, and deduplicates all tracing data before passing it to the OTEL collector for aggregation and export, with a visualization system at the end of the workflow to make the data usable. This approach gives users the widest range of choices for displaying and analyzing data, while taking advantage of the OTEL standard to simplify the earlier stages (collection, aggregation, and so on).
We built the implementation in two stages:
- Deploy the OpenTelemetry Operator for Kubernetes for managing an OTEL collector in the environment
- Instrument the Bank of Sirius application to emit traces and metrics
The original version of MARA used Elasticsearch with Filebeat for logging, and though we considered replacing them with Grafana Loki, we decided to keep the original choice for the time being. On the metrics front, we realized that we needed to revise the original deployment based on Prometheus and Grafana by replacing the bespoke Prometheus configuration we had initially used with the community‑maintained kube-prometheus-stack Helm chart, which stands up a complete Prometheus environment including Grafana, node exporters, and a series of pre‑configured dashboards and scrape targets suitable for managing a Kubernetes environment. To this we added in some additional dashboards for F5 NGINX Ingress Controller and the Bank of Sirius application.
This is only a short summary of the immense amount of work required to implement OTEL. To save others the effort of climbing the same steep learning curve, we’ve documented the entire process in Integrating OpenTelemetry into the Modern Apps Reference Architecture – A Progress Report on our blog.
Deployment Options – Kubeconfig
In the initial version of MARA we chose Amazon Elastic Kubernetes Service (EKS) as the deployment environment. Many users have since told us that for cost reasons they want to run MARA in “local” environments that require fewer resources, such as a lab or workstation. Portability was a key goal of the original project (and remains so), so this was our chance to prove that we could accomplish it. To make the task easier, we decided to design a deployment procedure that could run on any Kubernetes cluster that met some minimum requirements.
As a first step, we added a new Pulumi project to MARA that reads a kubeconfig file to communicate with the Kubernetes cluster. This project sits between Pulumi Kubernetes projects and infrastructure projects (examples of the latter being projects for AWS and Digital Ocean). In practical terms, creating the kubeconfig project lowers the barrier to integrating a new infrastructure project. If an infrastructure project can pass a kubeconfig file, cluster name, and cluster context to the kubeconfig project, the remainder of the MARA deployment procedure works seamlessly.
For our testing, we used several easy-to-install Kubernetes distributions with small CPU and memory requirements, including K3s, Canonical MicroK8s, and minikube. The distributions were all deployed on a virtual machine (VM) running Ubuntu 21.10 with 2 CPUs and 16 GB RAM. Additionally, all distributions were configured to provide persistent volumes and Kubernetes LoadBalancer support.
The most difficult part of this process was working with the private registry used for the custom‑built NGINX Ingress Controller that is part of the project. (Note that when deploying MARA you can use the standard NGINX Ingress Controller based on NGINX Open Source or NGINX Plus as well as this custom‑built NGINX Ingress Controller.) We discovered we needed to decouple our registry logic from Amazon Elastic Container Registry (ECR) in favor of a more platform‑agnostic approach, a task that is currently in progress. We also realized that our logic for pulling the hostname of the egress address was very specific to AWS Elastic Load Balancing (ELB), and needed to be rewritten to apply to other use cases.
The MARA management scripts and the Pulumi projects currently use some specific logic for working around the issues described above. For now, the Kubernetes configuration‑based deployments must use NGINX Ingress Controller (based on either NGINX Open Source or NGINX Plus) from the official NGINX registries.
We have added several tuning parameters to the MARA configuration files to accommodate local deployments that don’t offer the resources needed for cloud‑based deployment. Most parameters are related to the number of replicas requested for the various components of the Elastic Stack. As testing moves forward, there will be additional parameters for fine‑tuning MARA based on the resource constraints of the deployment environment.
With these changes in place, we can successfully deploy to K3s, MicroK8s, and Minikube, and we’ve successfully tested the logic on Azure Kubernetes Service (AKS), Digital Ocean, Google Kubernetes Engine, Linode, and Rancher’s Harvester. For more information, see the MARA Provider Status page and MARA: Now Running on a Workstation Near You on our blog.
Collaboration with Partners
Our partners have been very receptive and supportive of our work with MARA, with many of them reaching out to learn more about the project, ask how they can leverage it with their products, or even add features.
We chose Pulumi as a core part of MARA for its ease of use and support of Python, the latter being such a popular language that it makes the MARA code easily understood by a large community. Additionally, Pulumi’s vibrant community and engagement in the project was a model of the community involvement we hope to achieve with MARA.
In late 2021, we worked with Sumo Logic to make MARA a part of its cloud monitoring solution with NGINX Ingress Controller. This was a chance to put to the test our claim that MARA is pluggable. The challenge was to substitute the Sumo Logic solution for Grafana, Prometheus, and Elastic in MARA. We were pleased that we successfully stood up the solution using the same logic we use for other deployments, and configured it not only to connect to the Sumo Logic SaaS but also to pull metrics from our environment.
As part of our work with OpenTelemetry we collaborated with Lightstep, and easily reconfigured our OTEL collector to export traces and metrics to Lightstep’s SaaS offering. This is an area we are keen to investigate further, as we believe strongly that OTEL is the future of observability.
Lessons Learned…So Far
The biggest lesson we have learned so far is the wisdom of a modular approach. The work with Sumo Logic shows we can successfully mix and match MARA components. We expect further confirmation as we more fully integrate OTEL into the environment. We previously mentioned that we’re considering replacing Elasticsearch with Grafana Loki as the log management environment, because it reduces the resource footprint of the stack. That said, we advocate for “pragmatic modularity” rather than going to extremes by making everything a microservice. For example, while it makes sense to have a specialized service that can process logs for many applications, it is less obvious that you need separate microservices for log collection, storage, and visualization.
We have also been learning that it’s helpful to set defaults by including them explicitly in the configuration rather than just omitting the relevant parameter. This is convenient for administrators in two ways: they don’t have to remember the defaults and they can change them easily just by modifying a parameter that already appears with the correct syntax in the right place in the configuration.
Another painful lesson we learned is that some solutions are popular not because they’re the best, but because they’re the easiest to install or have the best tutorial. This is why it’s so important to question your assumptions and consult with colleagues during the design process – a culture of open communication goes a long way towards helping identify and remediate issues early on.
That said, on several occasions we implemented logic that worked but either painted us into a corner or caused other issues. For example, when we started deploying applications via Pulumi we used YAML manifests for ConfigMaps, relying on Pulumi transformations to update variables. This worked, but was not ideal for several reasons, not the least of which was maintainability. In the next iteration we improved the readability and maintainability of the code by using kube2pulumi to transform the manifests into Pulumi code that we could then use to build the ConfigMaps.
Another lesson started when a merge inserted invalid settings into the deployment YAML. We were forced to rewrite and carefully review large parts of the YAML to make sure the code was both syntactically correct and did what we wanted, a frustrating and time‑consuming process. To avoid future problems, we have now automated both generic YAML and Kubernetes‑specific linting and validation during the GitHub push process.
Finally, it has been our goal from the beginning to make sure that our mainline branch is always runnable. It is frustrating when you check out a new project and have to solve a problem that the maintainers introduced in the mainline. Unfortunately, we have failed at this a few times, including these examples with the Bank of Sirius submodule:
- We mistakenly forgot to change the URL scheme from ssh:// to https://. This wasn’t a problem for us, because we all use
sshto connect to GitHub. However, users who didn’t have a SSH key for GitHub were inundated with error messages when they tried to initialize the submodule. - One release of the management scripts had a dependency on a common package that we wrongly assumed would be installed on everyone’s machines as it is on ours.
- We forgot to put in a check for the submodule source during a rewrite of the startup logic. The submodule includes the manifests required to deploy Bank of Sirius, and unfortunately the errors and warnings thrown when these manifests were not available were obscure enough to set us on a multi‑day odyssey of debugging odd behavior before we discovered the root cause.
What’s Next
We have big plans for the next few months of development, including the refactoring of the NGINX Ingress Controller build, registry push, and ingress hostname/IP address logic.
One thing we’ve noticed with every standup of MARA is how quickly we start seeing scans and attacks on NGINX Ingress Controller. This has prompted us to begin integrating NGINX Ingress Controller with NGINX App Protect WAF into MARA. This brings with it the challenge and opportunity of determining how best to manage the logging produced by App Protect.
Another change we plan to make in the coming months is having all modules pull secrets from Kubernetes rather than from both Pulumi and Kubernetes. This means all modules use a common secrets repository and gives the administrator control over how secrets are populated. We’re writing a new module to read secrets from a repository of the user’s choosing and create the corresponding Kubernetes secrets.
MARA currently includes a tool for generating load that is an upgraded and slightly modified version of the Locust‑based tool that comes with the original Bank of Anthos app from which we forked Bank of Sirius. The new testing tool we’re writing, Cicada Swarm, not only generates load but also tracks and reports when metrics cross thresholds that you have set, making it a framework for rapid performance testing of software products in the cloud. It uses parallelization techniques to deliver test results with the confidence level you need, greater precision, and customizable regression analysis to determine the success or failure of builds in on your CI/CD pipelines.
Finally, we cannot mention load testing without talking about how we are going to measure the impact of that load testing, which takes us back to telemetry. We are excited about the potential of OpenTelemetry and hope to have a more comprehensive implementation in place soon. Even without a full implementation, our goal is to be able to run a test, measure its impact, and make operational decisions about what the data tells us.
As always, we welcome your pull requests, issues, and comments. Our goal with MARA is to inspire the community to work together to discuss, try, test, and iterate through different potential solutions in order to grow our understanding of how best to deploy and manage a modern application.
Related Posts
This post is part of a series. As we add capabilities to MARA over time, we’re publishing the details on the blog:
- A New, Open Source Modern Apps Reference Architecture
- Integrating OpenTelemetry into the Modern Apps Reference Architecture – A Progress Report
- MARA: Now Running on a Workstation Near You
- Announcing Version 1.0.0 of the NGINX Modern Apps Reference Architecture (this post)
About the Author
Related Blog Posts

Automating Certificate Management in a Kubernetes Environment
Simplify cert management by providing unique, automatically renewed and updated certificates to your endpoints.

Secure Your API Gateway with NGINX App Protect WAF
As monoliths move to microservices, applications are developed faster than ever. Speed is necessary to stay competitive and APIs sit at the front of these rapid modernization efforts. But the popularity of APIs for application modernization has significant implications for app security.
How Do I Choose? API Gateway vs. Ingress Controller vs. Service Mesh
When you need an API gateway in Kubernetes, how do you choose among API gateway vs. Ingress controller vs. service mesh? We guide you through the decision, with sample scenarios for north-south and east-west API traffic, plus use cases where an API gateway is the right tool.
Deploying NGINX as an API Gateway, Part 2: Protecting Backend Services
In the second post in our API gateway series, Liam shows you how to batten down the hatches on your API services. You can use rate limiting, access restrictions, request size limits, and request body validation to frustrate illegitimate or overly burdensome requests.
New Joomla Exploit CVE-2015-8562
Read about the new zero day exploit in Joomla and see the NGINX configuration for how to apply a fix in NGINX or NGINX Plus.
Why Do I See “Welcome to nginx!” on My Favorite Website?
The ‘Welcome to NGINX!’ page is presented when NGINX web server software is installed on a computer but has not finished configuring