
Production is not built to fail.
Traditional network and application services architectures are built to be reliable even in the face of failure. Redundancy and failover are critical capabilities of the infrastructure that sits between customers and an organization's most valuable asset: its applications.
Failover—true failover—cannot be achieved by simply spinning up a new container. This approach only works for modern applications that are designed to be stateless. That's rarely a characteristic of traditional applications, and it's not even a certainty for modern ones. Enterprise-class scale and reliability is critical to maintaining the availability of what remains the bulk of the enterprise application portfolio: traditional apps.
But that doesn't mean we should ignore the growing number of modern applications. Every new app architecture starts out with just a few projects and then explodes as organizations learn how to develop, deploy, and operate the systems and solutions required to scale and secure those new apps. The number of net-new applications being developed using modern architectures remains small within the enterprise, but it's growing fast. It has to if organizations are going to keep up in the digital economy.
Architecture at the Speed of Applications
More than one in five organizations now have fifty (50) or more major app requests in their application backlog. More than 61% have more than ten (10) new app requests in the queue. Traditional development approaches can’t keep up. More apps based on modern architectures will appear as organizations turn to Agile and microservices to help accelerate delivery.
And as they do, they will need a way to bridge the divide between the scale and reliability model of modern architectures and the demanding scale and reliability required to realize enterprise-level deployments.
Those modern architectures often include NGINX. In fact, one might say most emerging modern architectures rely on NGINX in one or more roles.
Among the top twelve application components you'll find running in containers is NGINX. Among the top (the very top, to be honest) of container ingress providers in use, you'll find NGINX. In every survey and data-based report on cloud, containers, and microservices, you are likely to find NGINX in a list of components running.
Primarily NGINX serves the need for scale in modern architectures. It offers reliability to modern apps in that if there is a failure of one app instance, NGINX will notice and direct subsequent requests to other app instances. It covers for the failure that is innately designed into container environments. It also satisfies the requirements for application uptime that most DevOps and developers are tasked with meeting.
But that doesn't necessarily translate to scaling an entire enterprise architecture and ensuring its reliability. The same “built to fail” system that works so well for modern applications isn't well-suited to providing the same for traditional apps and application services infrastructure. At the heart of the difference is a “state versus stateful” model. Modern apps aim to be stateless because that, in turn, makes the architecture work. Traditional apps—and the network itself—is stateful. Failure kills transactions and sessions in progress and disrupts availability.
Modern Reliability
The blast radius of a failure in production that impacts shared infrastructure (which is most of it) is large. Very large. Networks and application services responsible for the delivery and security of hundreds of applications are not built to fail, they are built to be reliable.
In the role of enterprise-class scale and reliability is F5 with BIG-IP. Designed for reliability and able to scale to meet both demand and massive attacks, BIG-IP is the means by which over 25,000 enterprises deliver apps. It satisfies requirements for network and application uptime that NetOps are tasked with meeting.
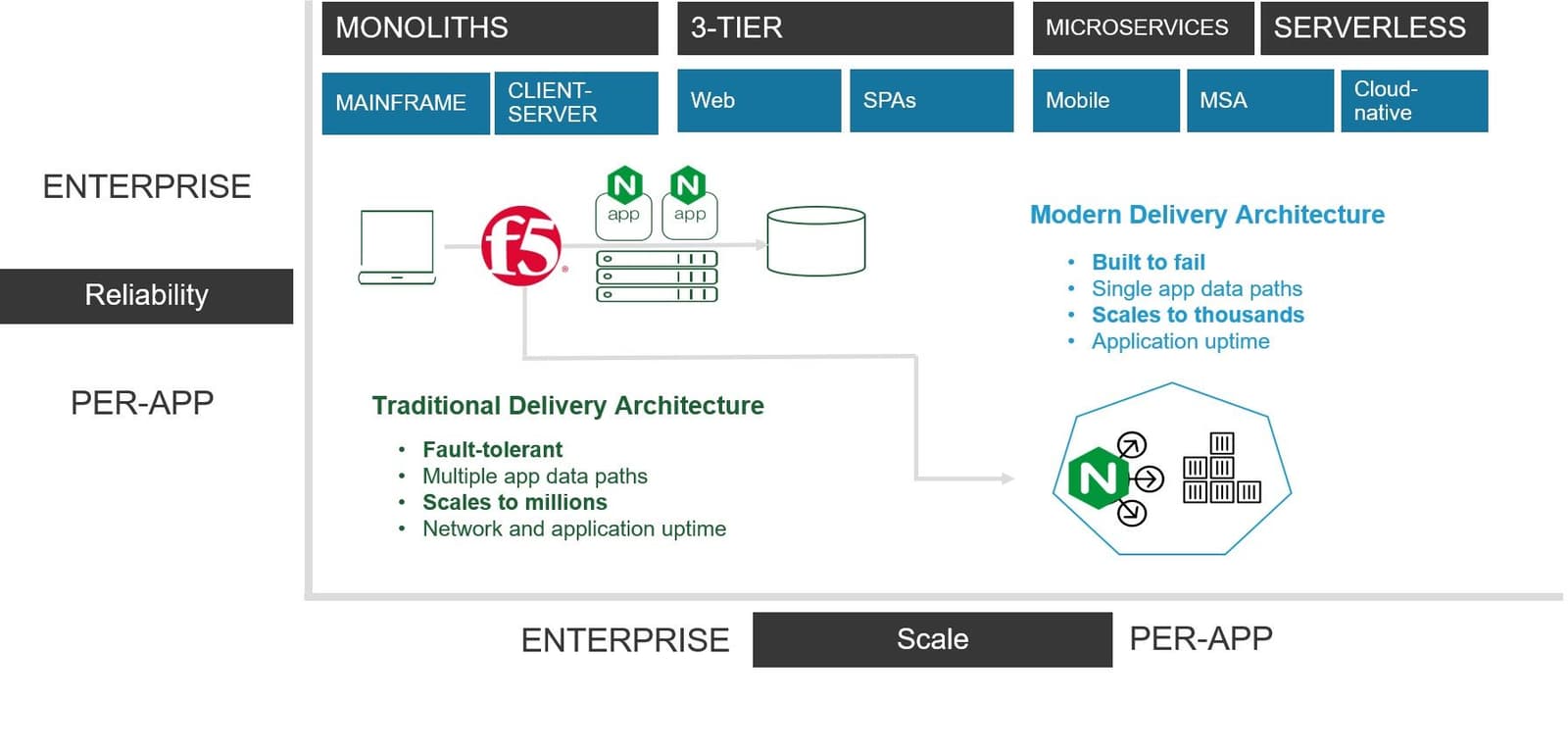
By bringing the two together, we will be able to satisfy the requirements for “reliable” no matter the definition. Whether that applies to the reliability of small, developer-driven deployments scaling modern apps or large deployments scaling application services and traditional apps alike, a combined portfolio will offer customers the ability to use the right tool for the right app.
For more about the advantages of bringing F5 and NGINX together, check out a post from F5’s CEO introducing the ‘Bridging the Divide’ blog series.
About the Author

Related Blog Posts

Why sub-optimal application delivery architecture costs more than you think
Discover the hidden performance, security, and operational costs of sub‑optimal application delivery—and how modern architectures address them.

Keyfactor + F5: Integrating digital trust in the F5 platform
By integrating digital trust solutions into F5 ADSP, Keyfactor and F5 redefine how organizations protect and deliver digital services at enterprise scale.

Architecting for AI: Secure, scalable, multicloud
Operationalize AI-era multicloud with F5 and Equinix. Explore scalable solutions for secure data flows, uniform policies, and governance across dynamic cloud environments.

Nutanix and F5 expand successful partnership to Kubernetes
Nutanix and F5 have a shared vision of simplifying IT management. The two are joining forces for a Kubernetes service that is backed by F5 NGINX Plus.

AppViewX + F5: Automating and orchestrating app delivery
As an F5 ADSP Select partner, AppViewX works with F5 to deliver a centralized orchestration solution to manage app services across distributed environments.

F5 NGINX Gateway Fabric is a certified solution for Red Hat OpenShift
F5 collaborates with Red Hat to deliver a solution that combines the high-performance app delivery of F5 NGINX with Red Hat OpenShift’s enterprise Kubernetes capabilities.