
The network is forking. Bifurcating. Dispersing. You’re welcome to use whatever term you’d like to use to describe the phenomenon of network services relocating from the quiet suburb that is the corporate network to hectic and noisy urban quarters on the application side of the data center network. The terminology isn’t the point of today’s discussion, rather today we’re going to excogitate on the reason why it’s happening.
Some might say “Well, Lori, it’s obvious that the corporate network is very much based in hardware and hardware just doesn’t have the flexibility and agility required to fit in with the more hip, agile environment going on in dev and ops.”

Well, no. It’s not so much about hardware or software because really, you have to have hardware no matter what you do (resources like RAM and compute and network access don’t materialize out of thin air, you know). It’s more about the operational culture and realities that govern each of the two networks that are driving some services from one side to the other.
In fact, I’d say that what’s really going on is that applications are now the center of gravity and they’re attracting all the application-affine services to them much in the same way the moon is attracted to the earth.
The thing is that application-affine services – like load balancing, caching, acceleration, and web app security – are all very peculiar to a given application. These are not “one size fits all” kind of services. On the contrary, these are highly focused, application-centric services whose policies are meant to deliver, secure, and optimize ONE application.
Not all of them. Not even all of the same kind. Just one. That one, over there.
This is very different from, say, a network firewall or IPS/IDS whose operation really isn’t all that specific to an application. Web apps run over port 80, so open that up and allow access through the firewall. There’s very little “application” specificity to that other than, well, they use the same protocol (HTTP) and run on the same port.
Conversely, setting a security policy that dictates what kind of data (string? integer? alphanumeric?) as well as how much data (15 characters? 12? 100?) can be associated with a single input field (username? email? comment?) that’s associated with a single URI (/login.x) is pretty doggone application specific. So are policies that govern minification, and concatenation of style sheets, and the health monitoring associated with an application in the load balancing service.
Why affinity matters
Now, the average enterprise is said to be managing about 508 applications. According to our research 31% of organizations actually have 500 or more, but that’s not the point either, it’s just a baseline. And it is a baseline because a whole lot of organizations are planning to build a whole lot more applications. And then there’s those organizations that are adopting a microservices architecture that aren’t necessarily changing the number of applications but they are changing the number of “systems”, if you will, that are going to need those aforementioned, application affine services.
So. Imagine if you will that an organization is looking at doubling the number of applications under management. Let’s say they started with 500 and now they’re going to suddenly have 1000. They need to provision, configure, and manage each and every policy. Let’s say every app only needs 2 – one for scale, and one for security – to make the math nice and easy. That’s 2000 policies you need to deal with. Ready? Go.
Yeah. The problem isn’t that the “hardware” in the corporate network can’t handle that. On the contrary, it can precisely because it is purpose-built hardware and thus has capacity far beyond a general purpose server. The problem is the processes and manpower needed to do it all. It’s not just the number of devices that are needed, it’s the number of unique (application-affine) policies that must be deployed.
And not just deployed, but updated. Because application-affine policies are configured specifically for an application, there is a greater likelihood that when an app is upgraded or a fix is introduced its associated app service policies may need updating too. And with orgs wanting to deploy more frequently, well.. you can imagine the corporate network folks would be completely overwhelmed.
On the other side of the fence, in the app network, dev and ops are hungry. Hungry to get apps delivered and deployed. They’re ready to use their new skills in automation and orchestration to speed up that process.
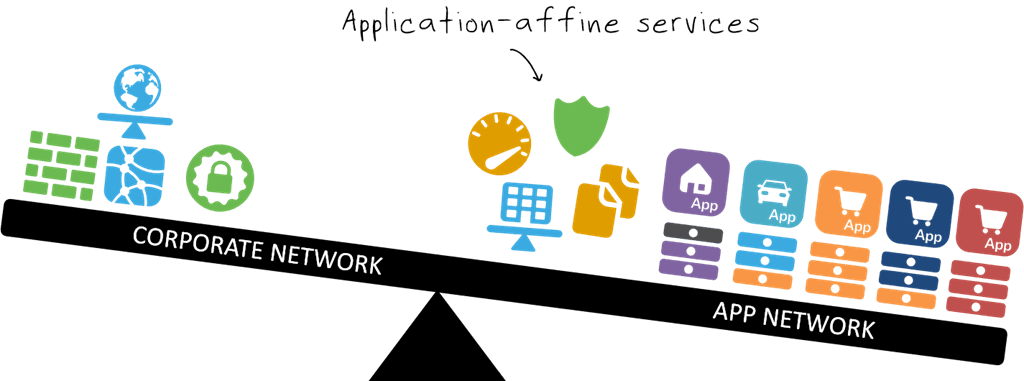
And so they are, by taking on responsibility for more and more application-affine services and incorporating them into their deployment architectures and processes. With increasing awareness of DevOps and some industry encouragement from SDN, network services are almost all enabled with APIs. Many others are enabled with templates that fit like a glove onto the hand of operators employing an “infrastructure as code” approach to managing and deploying the infrastructure required to support applications.
Which is why more and more “application services” are turning up in the application network and shifting the center of gravity in enterprise IT toward the application.
It’s a business and operational scaling strategy. It’s a way to deal with the rapid growth in the application portfolio without running afoul of Brooks’ law by throwing more network or application headcount at the problem. It’s a way to enable IT to deliver apps to the market faster, and more frequently, without the disruption caused by suddenly requiring network operators to manage two or three or more times the number of policies they do right now.
About the Author

Related Blog Posts

Why sub-optimal application delivery architecture costs more than you think
Discover the hidden performance, security, and operational costs of sub‑optimal application delivery—and how modern architectures address them.

Keyfactor + F5: Integrating digital trust in the F5 platform
By integrating digital trust solutions into F5 ADSP, Keyfactor and F5 redefine how organizations protect and deliver digital services at enterprise scale.

Architecting for AI: Secure, scalable, multicloud
Operationalize AI-era multicloud with F5 and Equinix. Explore scalable solutions for secure data flows, uniform policies, and governance across dynamic cloud environments.

Nutanix and F5 expand successful partnership to Kubernetes
Nutanix and F5 have a shared vision of simplifying IT management. The two are joining forces for a Kubernetes service that is backed by F5 NGINX Plus.

AppViewX + F5: Automating and orchestrating app delivery
As an F5 ADSP Select partner, AppViewX works with F5 to deliver a centralized orchestration solution to manage app services across distributed environments.

F5 NGINX Gateway Fabric is a certified solution for Red Hat OpenShift
F5 collaborates with Red Hat to deliver a solution that combines the high-performance app delivery of F5 NGINX with Red Hat OpenShift’s enterprise Kubernetes capabilities.