Im Containerland ist die deklarative Konfiguration König

Die digitale Transformation im Inneren ist von entscheidender Bedeutung, um die digitale Transformation im Äußeren zu ermöglichen. Eine der grundlegenden Komponenten der internen digitalen Transformation ist die Automatisierung, die in hohem Maße auf der Steuerungsebene basiert. Die Automatisierung findet auf der Steuerebene statt. In den alten Computertagen bezeichneten wir es als „Verwaltungsnetzwerk“ und verwendeten Protokolle wie SNMP zur Überwachung, Konfiguration und Steuerung.
Heute existiert das Verwaltungsnetzwerk zumindest theoretisch noch immer als Medium, über das wir dieselben Aufgaben über die Steuerebene ausführen. Die Steuerebene ist ein unübersichtliches Gebiet aus APIs, Masterknoten und sogar Nachrichtenwarteschlangen, die es einzelnen Komponenten in einem komplexen verteilten System ermöglichen, sich (fast) automatisch selbst zu verwalten. Sie erfolgt zunehmend ereignisgesteuert, was ein Umdenken gegenüber den zentralisierten Befehls- und Kontrollmodellen der Vergangenheit erfordert, die sich in erster Linie auf imperative Managementmodelle stützten. Das heißt, ein zentrales System weist Komponenten implizit durch bestimmte API-Aufrufe an, Änderungen herbeizuführen. Die heutigen Umgebungen basieren dagegen auf deklarativen Modellen, die die Verantwortung für Änderungen selbst verteilen.
In keinem System ist dies deutlicher als in Containerumgebungen. Von außen betrachtet wirken solche Systeme beinahe abtrünnig; Nachrichten und Ereignisse werden nach Belieben veröffentlicht und gesendet, ohne dass es einen Oberherrn gibt, der bestimmt, wer oder was darauf reagieren soll. Bei der Kontrollebene geht es nicht mehr so sehr um Kontrolle, sondern vielmehr um die Verteilung über eine Ebene, die eher einem Netz als den Hub-and-Spoke-Architekturen archaischer Verwaltungssysteme entspricht. In der traditionellen Welt haben wir APIs und Protokolle verwendet, um Änderungen an Komponenten vorzunehmen. In der digitalen, containerisierten Welt nutzen wir APIs, um die Informationen abzurufen, die eine Komponente für ihre Selbständerung benötigt.
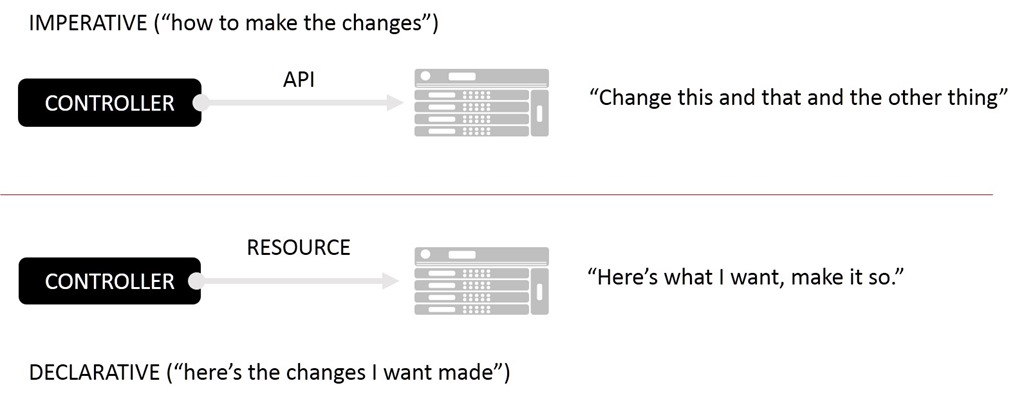
Diese neue Welt ist reaktiv und verzichtet auf das imperative (API-gesteuerte) Modell der traditionellen Steuerungsebene. Stattdessen verlässt sie sich auf ein offeneres, deklarativeres Modell, um den gewünschten automatisierten Endzustand zu erreichen.
Das ist nicht überraschend. Da wir bei allen Bereichen zunehmend einen softwaregesteuerten Ansatz verfolgen (unter dem Deckmantel von DevOps, Cloud und NFV), mussten wir uns gleichzeitig mit enormen betrieblichen Größenordnungen auseinandersetzen. Ein imperatives Hub-and-Spoke-Managementmodell lässt sich nicht effizient skalieren, da die Last für alle Änderungen auf einem zentralen Controller liegt, der über eine verwirrende Anzahl von APIs mit einer nahezu unbegrenzten Gruppe von Komponenten kommunizieren kann. Dies ist ein „Push“-Modell, bei dem der Manager (Controller) Änderungen an jede betroffene Komponente überträgt. Es wird zum Engpass, der über Erfolg oder Misserfolg des gesamten Systems entscheidet.
Zur Skalierung und Entlastung des Controllers ist ein ereignisgesteuertes Modell erforderlich, das auf Pull-by-Komponenten basiert. Dies erfordert wiederum, dass Komponenten, die an dieser Steuerungsebene teilnehmen möchten, mit einem deklarativen Konfigurationsmodell zurechtkommen. Denn statt Änderungen über eine API zu pushen (imperativ), drängen uns Container dazu, Änderungen stattdessen über deklarative Konfigurationen zu pullen. Es liegt in der Verantwortung der Komponentenanbieter (ob Open Source oder kommerziell), die Änderungen korrekt zu abonnieren und dann die entsprechenden Informationen abzurufen, die für die sofortige Implementierung dieser Änderungen erforderlich sind.
Wenn das nach Infrastruktur als Code klingt, dann ist das auch so. Deklarative Konfigurationen sind grundsätzlich Code oder zumindest Codeartefakte. Die Automatisierung beruht zunehmend auf der Prämisse, die Konfiguration vom Service zu entkoppeln. In einem idealen utopischen Modell sind diese deklarativen Konfigurationen völlig agnostisch. Das heißt, sie wären von jedem Produkt jedes Anbieters (kommerziell oder Open Source) lesbar, das diesen Dienst unterstützt. Beispielsweise könnte eine deklarative Konfiguration, die den entsprechenden Dienst (virtuellen Server) und die Apps beschreibt, die seinen Ressourcenpool beeinträchtigen, von Dienst X oder Dienst Y aufgenommen und implementiert werden.
Kubernetes-Ressourcendateien sind ein gutes Beispiel für ein deklaratives Konfigurationsmodell, in dem beschrieben wird, was gewünscht wird, aber nirgends vorgeschrieben ist , wie . Dies unterscheidet sich deutlich von Systemen, die auf Infrastruktur-APIs basieren, bei denen die Implementierung – manchmal sogar sehr genau – mit der Art und Weise vertraut sein muss, wie die gewünschten Ergebnisse erzielt werden.
Das deklarative Modell ermöglicht es auch, Infrastruktur wie Vieh zu behandeln. Wenn eine Instanz ausfällt, können Sie sie ganz einfach beenden und eine neue Instanz starten. Die gesamte erforderliche Konfiguration befindet sich in der Ressourcendatei. Es gibt keine Schaltfläche „Speichern Sie Ihre Arbeit, sonst geht sie verloren“, da keine Arbeit verloren gehen kann. Diese ist nahezu unveränderlich und stellt definitiv eine Wegwerf-Infrastruktur dar. In Systemen, die sich minütlich, wenn nicht sogar sekündlich ändern, ist sie eine Notwendigkeit, um die Auswirkungen von Fehlern zu minimieren.
Da wir uns immer mehr in Richtung automatisierter Skalierungs- und – darf ich das behaupten? – Sicherheitssysteme bewegen, müssen wir uns für die Verwaltung der unzähligen Geräte und Dienste, aus denen der Anwendungsdatenpfad besteht, auf deklarative Modelle stützen. Sonst laufen wir Gefahr, unter einer Lawine von Betriebsschulden begraben zu werden, die durch manuelle Integrations- und Automatisierungsmethoden entstehen.