
This blog post is one in a series about AI factories. When you are finished here, explore the other posts in the series.
- Retrieval-Augmented Generation (RAG) for AI Factories ›
- Optimize Traffic Management for AI Factory Data Ingest ›
- Optimally Connecting Edge Data Sources to AI Factories ›
- Multicloud Scalability and Flexibility Support AI Factories ›
- The Power and Meaning of the NVIDIA BlueField DPU for AI Factories ›
- API Protection for AI Factories: The First Step to AI Security ›
- The Importance of Network Segmentation for AI Factories ›
- AI Factories Produce the Most Modern of Modern Apps: AI Apps ›
When ChatGPT was released in November 2022, the questions we asked and prompts we entered were simple: "Tell me a story about X" and "Write a narrative between person A and person B on topic Z." Through these questions and initial interactions with GPT-3.5 at the time, we were trying to identify how this new, trending technology would impact our day-to-day lives. Now in late 2024, AI complements our lives: helping us debug and write code, compile and summarize data, and drive in autonomous vehicles, to name just a few. These are outputs of a modern-day AI factory, and we are only at the beginning.
This article, the first in a series on AI factories, explores the components of an AI factory and how the different elements work together to generate AI-driven solutions at scale.
Defining AI factories
Amidst the AI evolution, the concept of an AI factory has emerged as an analogy for how AI models and services are created, refined, and deployed. Much like a traditional manufacturing plant that takes materials and transforms them into finished goods, an AI factory is a massive storage, networking, and computing investment serving high-volume, high-performance training and inference requirements.
“An AI factory is a massive storage, networking, and computing investment serving high-volume, high-performance training and inference requirements.”
Within these factories, networks of servers, graphics processing units (GPUs), data processing units (DPUs), and specialized hardware work in tandem to process vast amounts of data, executing complex algorithms that train AI models to achieve high levels of accuracy and efficiency. These infrastructures are meticulously designed to handle the immense computational power required for training large-scale models and deploying them for real-time inference. They incorporate advanced storage solutions to manage and retrieve massive datasets, ensuring seamless data flow.
Load balancing and network optimization maximize performance and resource utilization, preventing bottlenecks and ensuring scalability. This orchestration of hardware and software components allows AI factories to produce cutting-edge AI models and continuously refine them, adapting to new data and evolving requirements. Ultimately, an AI factory embodies the industrialization of AI development, providing the robust infrastructure needed to support the next generation of intelligent applications.
Why do AI factories matter?
As NVIDIA CEO Jensen Huang said at Salesforce Dreamforce 2024, “In no time in history has computer technology moved faster than Moore’s law,” continuing, “We’re moving way faster than Moore’s law and are arguably easily Moore’s law squared.”
Deploying AI at scale is becoming increasingly essential as AI investments serve as crucial market differentiators and drivers of operational efficiency. To achieve this, organizations need to continuously build and refine models and integrate knowledge repositories and real-time data. The AI factory concept highlights that AI should be an ongoing investment rather than a one-time effort. It provides a framework for organizations to operationalize their AI initiatives, making them more adaptable to changing business and market demands.
Components of an AI factory
Drawing on our expertise helping customers deploy high-performing, secure modern application fleets at scale, F5 has developed an AI Reference Architecture Framework. Given that AI apps are the most modern of modern apps, heavily connected via APIs and highly distributed, this framework addresses the critical performance, security, and operational challenges essential for delivering cutting-edge AI applications.

Seven AI building blocks
Within our reference architecture, we have defined seven AI building blocks needed to build out a comprehensive AI factory:
1. Inference
Outlines the interaction between a front-end application and an inference service API; centers on sending a request to an AI model and receiving a response. This sets the groundwork for more intricate interactions.

2. Retrieval-Augmented Generation
Enhances the basic Inference by adding large language model (LLM) orchestration and retrieval augmentation services. It details retrieving additional context from vector databases and content repositories, which is then used to generate a context-enriched response.

3. RAG corpus management
Focuses on the data ingest processes required for Inference with retrieval augmented generation (RAG). It includes data normalization, embedding, and populating vector databases, preparing content for RAG calls.

4. Fine-tuning
Aims to enhance an existing model's performance through interaction with the model. It adjusts the model without rebuilding it from scratch and emphasizes collecting data from Inference and Inference with RAG for fine-tuning workflows.

5. Training
Involves constructing a new model from the ground up, although it may use previous checkpoints (re-training). It covers data collection, preprocessing, model selection, training method selection, training, and validation/testing. This iterative process aims to create robust models tailored to specific tasks.

6. External service integration
Connects the LLM orchestration layer to external sources like databases and websites. It integrates external data into inference requests but does not include document preprocessing tasks such as chunking and embedding.

7. Development
Encompasses workflows for developing, maintaining, configuring, testing, and deploying AI application components. It includes front-end applications, LLM orchestration, source control management, and CI/CD pipelines.
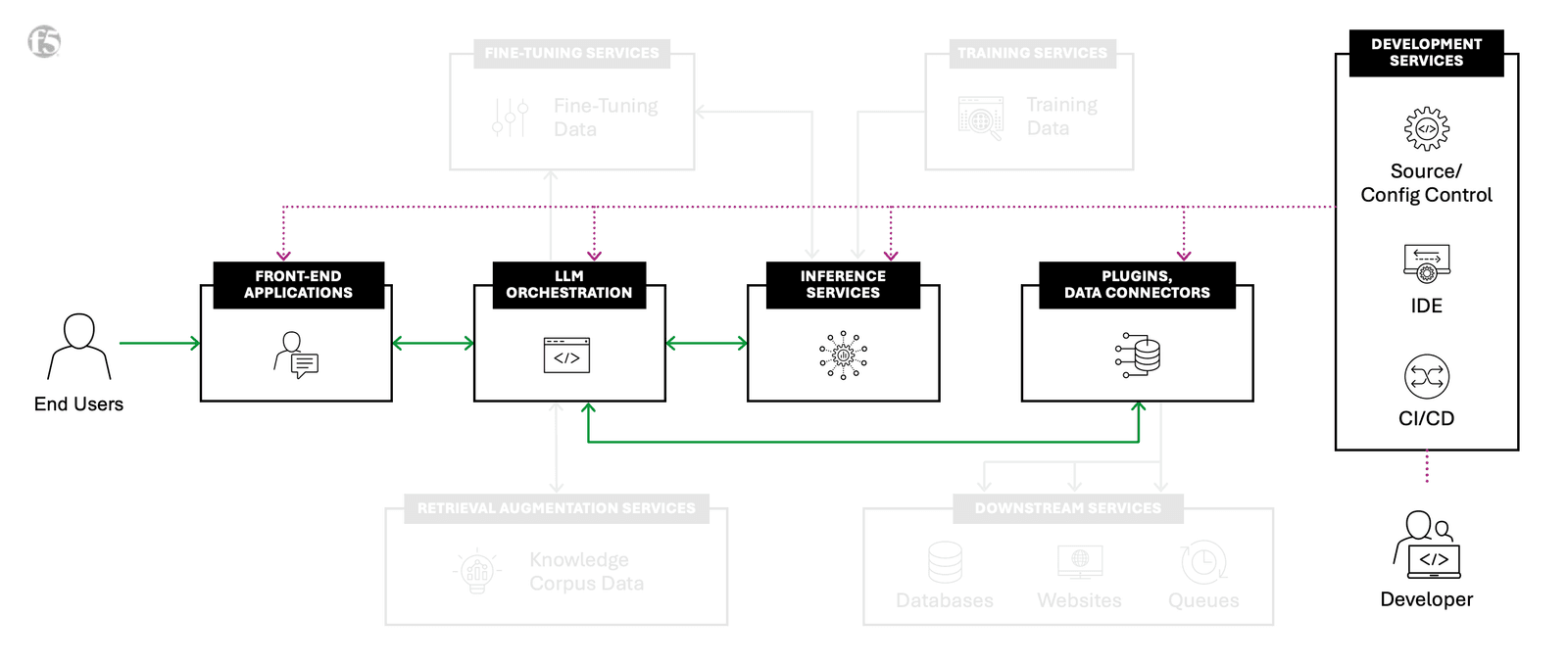
Together, these building blocks form the backbone of an AI factory. Each plays a crucial role in the creation, deployment, and refinement of AI outputs. In addition, AI factory initiatives tend to lend themselves to owning one’s implementation strategies (over leasing or out-sourcing them) for most of the building blocks, resulting in the selection of self-hosted out of the below-listed deployment models.
Four deployment models
For each of these building blocks, customers must select an appropriate deployment model and implementation strategy (own, lease, or out-source), defining the optimal reference architecture for achieving the business objectives of their AI initiatives. Here are the top four:
- AI-SaaS involves using a Software as a Service (SaaS) implementation of an inference service, where the service provider manages the infrastructure, model updates, and scaling. Users interact with the service through APIs without worrying about underlying maintenance. This deployment model is ideal for businesses seeking ease of use and quick integration without significant overhead. It also allows for rapid scalability and access to the latest features and improvements.
- Cloud-hosted deployment involves managing the inference service using a cloud service provider (CSP) as Infrastructure as a Service (IaaS) or Platform as a Service (PaaS). In this model, the user is responsible for managing the service, including configuration, scaling, and maintenance, but benefits from the CSP's robust infrastructure and tools. This model offers flexibility and control, making it suitable for organizations with specific requirements and technical expertise. It also enables seamless integration with other cloud-native services and tools.
- Self-hosted deployment requires managing the inference service within a self-managed private data center or collocation service. This model provides the highest level of control and customization, allowing organizations to tailor the infrastructure and service to their specific needs. However, it also demands significant resources for maintenance, updates, and scaling. It is often chosen by organizations with stringent security, compliance, or performance requirements that cannot be met by cloud-based solutions.
- Edge-hosted deployment involves running AI or machine learning (ML) services at the edge, such as in a retail kiosk, IoT device, or other localized environments. This model reduces latency by processing data close to its source, making it ideal for real-time applications and scenarios where Internet connectivity is limited or intermittent. It requires robust local hardware and software management but offers significant benefits for use cases requiring immediate, localized decision-making. Edge-hosted deployment is particularly valuable in industries like retail, manufacturing, and healthcare.
F5 delivers and secures AI applications anywhere
The capabilities from F5 you rely on day to day for application delivery and security are the same capabilities critical for a well-designed AI factory. F5 BIG-IP Local Traffic Manager, paired with F5 rSeries and VELOS purpose-built hardware, enables high-performance data ingest for AI training. F5 Distributed Cloud Network Connect for secure multicloud networking connects disparate data locations, creating a secure conduit from proprietary data to AI models for RAG.
F5’s focus on AI doesn’t stop here—explore how F5 secures and delivers AI apps everywhere.
Interested in learning more about AI factories? Explore others within our AI factory blog series:
- Retrieval-Augmented Generation (RAG) for AI Factories ›
- Optimize Traffic Management for AI Factory Data Ingest ›
- Optimally Connecting Edge Data Sources to AI Factories ›
- Multicloud Scalability and Flexibility Support AI Factories ›
- The Power and Meaning of the NVIDIA BlueField DPU for AI Factories ›
- API Protection for AI Factories: The First Step to AI Security ›
- The Importance of Network Segmentation for AI Factories ›
- AI Factories Produce the Most Modern of Modern Apps: AI Apps ›
About the Author

Hunter Smit is a senior manager of product marketing for solutions at F5. He leads solution-level go-to-market efforts focused on AI use cases and expansion into new markets, including initiatives for AI data delivery. Hunter holds undergraduate and graduate degrees in business administration from Whitworth University and is a member of the Whitworth School of Business Advisory Board.
More blogs by Hunter SmitRelated Blog Posts
F5 joins the Dell AI Ecosystem Program to help enterprises operationalize AI
F5 joins the Dell AI Ecosystem Program to help enterprises deploy production AI with greater performance, security, and control.
Why sub-optimal application delivery architecture costs more than you think
Discover the hidden performance, security, and operational costs of sub‑optimal application delivery—and how modern architectures address them.

Keyfactor + F5: Integrating digital trust in the F5 platform
By integrating digital trust solutions into F5 ADSP, Keyfactor and F5 redefine how organizations protect and deliver digital services at enterprise scale.

Architecting for AI: Secure, scalable, multicloud
Operationalize AI-era multicloud with F5 and Equinix. Explore scalable solutions for secure data flows, uniform policies, and governance across dynamic cloud environments.

AppViewX + F5: Automating and orchestrating app delivery
As an F5 ADSP Select partner, AppViewX works with F5 to deliver a centralized orchestration solution to manage app services across distributed environments.

F5 NGINX Gateway Fabric is a certified solution for Red Hat OpenShift
F5 collaborates with Red Hat to deliver a solution that combines the high-performance app delivery of F5 NGINX with Red Hat OpenShift’s enterprise Kubernetes capabilities.