
In summer 2024, Nvidia founder and CEO Jensen Huang offered that, “a new type of data center AI factories produce a new commodity: artificial intelligence.” So, let’s frame AI as if it were a physical commodity. Doing this conjures up images of Ford’s River Rouge Complex—an embodiment of vertical integration and industrialization. Iron and rubber went in one side, Ford automobiles came out the other. With its own docks, 100 miles of interior railroad track, a dedicated electricity plant, and even its own integrated steel, glass, and paper mills, The Rouge ran 24 hours day and made almost 1.5 million cars a year.
Similarly, the AI factories of today and of the future that serve high-volume, high-performance training and inference models ingest massive amounts of raw ingredients. Namely, data. Structured, unstructured, video, text, and beyond. These factories transform this data into tokenized outputs that can be leveraged across myriad applications. And just as The Rouge Complex needed precise control over each stage of production, AI workloads require robust traffic management systems to handle data ingestion, processing, and delivery—in a word: logistics. The right traffic management solutions give AI factories the ability to take raw ingredients from the field and make them usable. With the right logistical tools in place, teams can ensure seamless data flow, high throughput, low latency, and security, akin to keeping an assembly line running smoothly at every stage.
What every AI factory requires
Harvard Business Review in 2020 outlined how Alibaba affiliate Ant Group creates actionable intelligence from their AI factory to “manage a variety of businesses, serving [over] 10 times as many customers as the largest U.S. banks—with less than one-tenth the number of employees.” The way that Ant Group conceptualizes an AI factory build is equally compelling:
“Four components are essential to every factory. The first is the data pipeline, the semiautomated process that gathers, cleans, integrates, and safeguards data in a systematic, sustainable, and scalable way. The second is algorithms, which generate predictions about future states or actions of the business. The third is an experimentation platform, on which hypotheses regarding new algorithms are tested to ensure that their suggestions are having the intended effect. The fourth is infrastructure, the systems that embed this process in software and connect it to internal and external users.”
Earlier in our AI factory series, F5 defined an AI factory as a massive storage, networking, and computing investment serving high-volume, high-performance training and inference requirements. This is why the first and forth components in Ant Group’s list are especially intriguing: the challenge of establishing the systems needed to safely and efficiently manage data that AI models ingest brings front and center the question of how AI factories should develop the infrastructure around them to produce value.
Traffic management for AI data ingest is the unceasing process through which multi-billion-parameter, media-rich AI data traffic is managed and transported into an AI factory for machine learning and training purposes. This is where a high-performance traffic management solution comes into play to get that traffic into the AI factory. Without such a solution, teams may quickly find themselves needing to re-use connections to keep traffic flowing or hitting storage infrastructure limits, neither of which are ideal for the high-capacity, low-latency data transportation requirements AI factories demand to run at their desired, optimized, pace and scale.
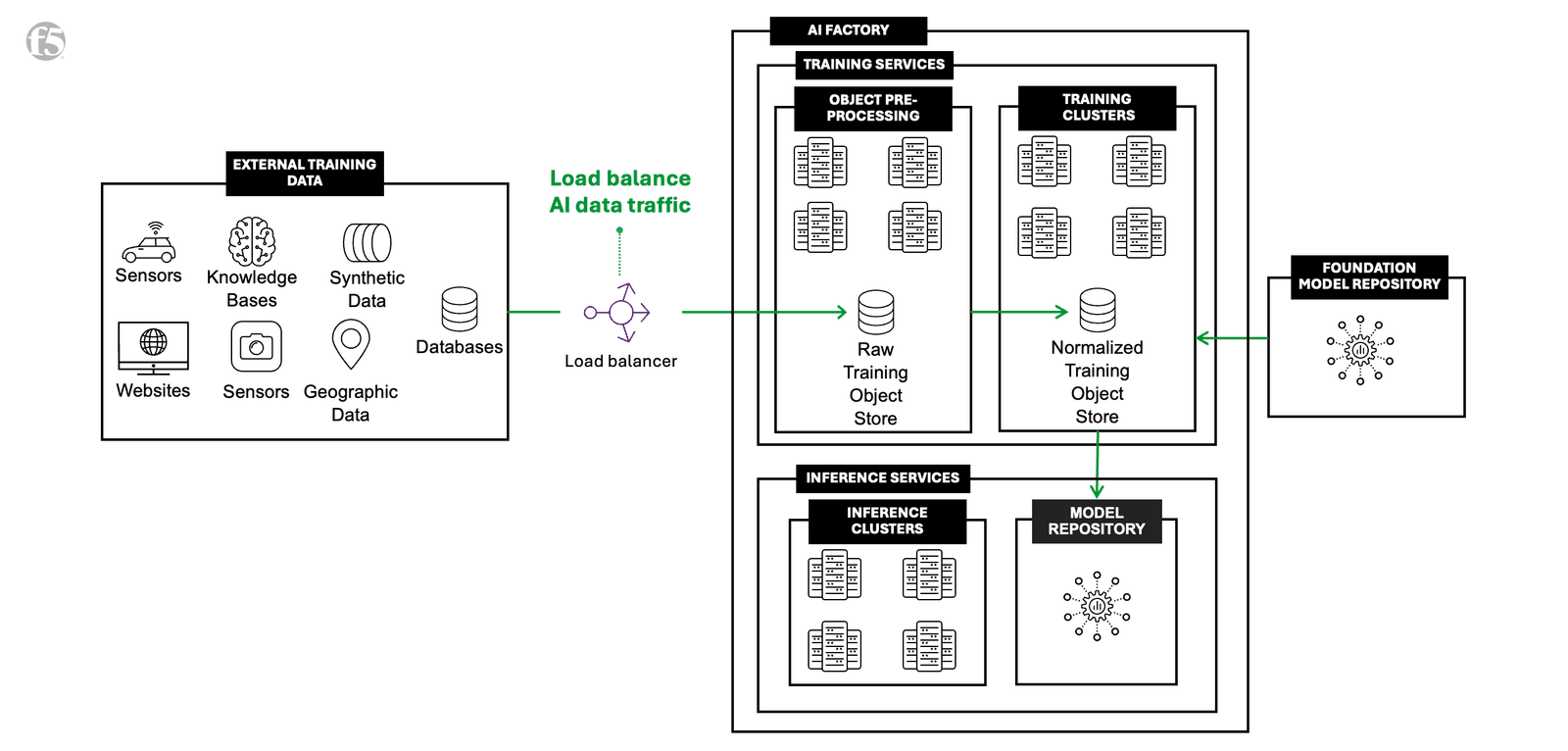
Managing AI Data traffic traveling to, through, and between AI factories.
“AI factories require high-performance traffic management solutions for data ingest of multi-billion, and soon multi-trillion, parameter AI models.”
Keeping the AI factories running
But the rate of progression in this field is far from stagnant. Increasingly complex AI models require greater amounts of data input at growing frequencies. This introduces a data gravity challenge, as the placement of data in a cloud or on prem matters greatly within an AI model. An AI factory built to withstand the gravitational pull from AI data demands of the future needs infrastructure that can scale to keep up with the requirements for faster insight from the data it receives. AI factory infrastructure can ultimately make or break the success and business value of the AI model it supports. This rapid growth in consumption of rich media can significantly escalate network traffic and associated costs if processed through some cloud providers. Thus, enterprises grappling with this situation face a dual challenge: maintaining the high-speed data throughput required for efficient AI learning models and managing the complexities and expenditures tied to data transit and processing in the cloud.
Carefully vetting the four AI factory deployment types outlined in the initial article on AI factories (AI-SaaS, cloud-hosted, self-hosted, or edge-hosted) can help enterprises manage these complexities by eliminating or reducing reliance on cloud bandwidth. Processing data locally not only removes the question of cloud bandwidth from the equation. It also gives full control over sensitive training data sets. This, in turn, makes it easier to meet regulatory requirements (e.g., GDPR, HIPAA, or PCI DSS) as organizations can control how data is stored, accessed, and processed, while minimizing data exposure by keeping sensitive information within an organization’s secure network.
Better infrastructure equals more value for AI factories
AI data traffic and application traffic interact with F5 BIG-IP Local Traffic Manager (LTM) and next-gen hardware solutions in a similar manner. This means that, just like optimizing traditional application traffic flows, teams can optimize their AI data traffic flows with tools like the FastL4 profile, increasing virtual server performance and throughput. They can leverage TCP optimizations to fine-tune how systems handle TCP connections, critical to network performance. They can even deploy BIG-IP’s OneConnect, increasing network throughput by efficiently managing connections created between their BIG-IP systems and back-end pool members. Organizations looking for a solution to distribute AI data traffic between AI factories don’t have to look far to find one. F5 has been developing tools to optimize app traffic management for over two decades, making BIG-IP LTM ideal for handling AI data ingest traffic.
AI applications are the most modern of modern applications. Without a robust, versatile traffic management solution in place, usable data languishes in the field and the value that an AI model can reap from it evaporates. The Rouge had its docks and miles of train track, AI factories have F5 solutions like BIG-IP.
F5’s focus on AI doesn’t stop here—explore how F5 secures and delivers AI apps everywhere.
Interested in learning more about AI factories? Explore others within our AI factory blog series:
- What is an AI Factory? ›
- Retrieval-Augmented Generation (RAG) for AI Factories ›
- Optimally Connecting Edge Data Sources to AI Factories ›
- Multicloud Scalability and Flexibility Support AI Factories ›
- The Power and Meaning of the NVIDIA BlueField DPU for AI Factories ›
- API Protection for AI Factories: The First Step to AI Security ›
- The Importance of Network Segmentation for AI Factories ›
- AI Factories Produce the Most Modern of Modern Apps: AI Apps ›
About the Author

Griff Shelley is a Product Marketing Manager at F5, specializing in hardware, software, and SaaS application delivery solutions. With a passion for connecting innovative technology to customer success, Griff drives go-to-market projects in global and local app delivery, cloud services, and AI data traffic infrastructure. Prior to his career in tech, he was a post-secondary education academic advisor and earned degrees from Eastern Washington University and Auburn University.
More blogs by Griff ShelleyRelated Blog Posts

Secure-by-design storage for agentic AI: Why runtime visibility plus traffic control matters
Learn how F5 is collaborating with NVIDIA to help protect agentic AI with secure-by-design AI infrastructure, runtime visibility, and traffic control.
F5 joins the Dell AI Ecosystem Program to help enterprises operationalize AI
F5 joins the Dell AI Ecosystem Program to help enterprises deploy production AI with greater performance, security, and control.
Why sub-optimal application delivery architecture costs more than you think
Discover the hidden performance, security, and operational costs of sub‑optimal application delivery—and how modern architectures address them.

Architecting for AI: Secure, scalable, multicloud
Operationalize AI-era multicloud with F5 and Equinix. Explore scalable solutions for secure data flows, uniform policies, and governance across dynamic cloud environments.

AppViewX + F5: Automating and orchestrating app delivery
As an F5 ADSP Select partner, AppViewX works with F5 to deliver a centralized orchestration solution to manage app services across distributed environments.

F5 NGINX Gateway Fabric is a certified solution for Red Hat OpenShift
F5 collaborates with Red Hat to deliver a solution that combines the high-performance app delivery of F5 NGINX with Red Hat OpenShift’s enterprise Kubernetes capabilities.