
One of the catch phrases of DevOps and cloud for the past, oh, many years has been “build to fail.” The premise being that too many businesses experience costly downtime and loss of revenue (and productivity) due to capacity-related performance problems so you should build your app and infrastructure ‘to fail’ to ensure such ghastly events do not come back to haunt you. Heh. See what I did there? Yes, I work remotely in an office, alone. Sometimes I have to amuse myself.
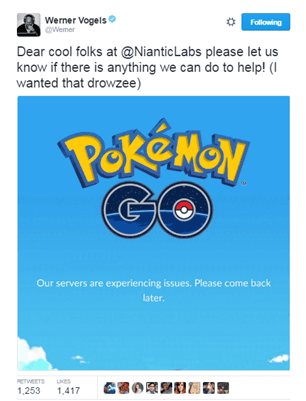
Bad puns aside, the recent phenomenal success of Pokémon Go (you did hear about that, right?) resulted in what was also a phenomenally frustrating experience for many. Especially parents with hyper-excited children who wanted to go, NOW, but couldn’t because account creation was temporarily suspended and then strictly metered because of overwhelming demand.

Now, some might point to Amazon CTO Werner Vogels’ offer to help the company deal with its capacity issues as implying they hadn’t “gone cloud” in the first place and that was the underlying problem, but that’s assuming they hadn’t, which is not quite clear to me at this point. Seriously, according to Wikipedia updates on the augmented reality developer, it processes “more than 200 million game actions per day as people interact with real and virtual objects in the physical world.” I think we can give them a bit of a break on this one, or at least those of us who understand what that means in terms of system interactions and pushing packets can. Updates pointed to “server issues” but come on, we all know that “server” is tech-code for “15 different components spread across the app and network infrastructure”.
At any rate, the underlying lesson here is not that cloud is necessarily better at dealing with unexpected success. It very well may be, but not because it’s cloud. It’s because cloud is not only built to fail but it is also built to scale.
I’m not in a position to determine why Niantic Labs was unable to keep up with demand. Perhaps it was a lack of capacity, in which case cloud would be a good choice, and perhaps it was that the apps and/or infrastructure wasn’t built to scale, in which case cloud might not have helped at all. The point is really not to poke (heh) at them for what they did/didn’t do. The point is that they are a perfect example of the reality that in an application world, organizations should be as concerned with building for failure as they are with building for success. And not just gradual success, but instant, overnight, Pokémon Go like success.
Because if it happens, you don’t want to have that successful failure plastered across the Internet.
A common source of scalability issues are with data sources. Seasoned Twitter users will remember that the social media’s early days were plagued by database scalability challenges. PayPal was one of the earliest and most vocal proponents of sharding as a scaling strategy to deal with its challenge around massive scale of users, and the technique has been adopted as a general one, applicable to databases, performance services, and applications alike. The rise of NoSQL data sources touts as one of its benefits greater scalability than traditional relational databases.
Another source of scalability issues lies solely on the shoulders of infrastructure. Auto-scaling in the cloud relies on the ability to not just automatically add more compute, but to increase capacity of the “app endpoint”. In any architecture relying on scale to achieve an increase in capacity that means a load balancing service of some kind. When compute is increased, it must be registered with the load balancing service. This means the use of APIs and scripts, automation and orchestration. These components must be in place before they are needed, or there will be delays should demand require an increase in capacity.
The inclusion of a load balancing service in any – every – app architecture should be a requirement. Not only does a load balancing service provide for the need to “build to fail” due to their inherent support for failover between two application instances, but it also supports the need to “build to scale” necessary to success. But don’t think it’s just slapping a load balancing service in front of an app (or microservice, if that’s your thing). It’s important for ops to put in place the automation (scripts) and orchestration (process) that will enable auto-scaling to meet that demand when it comes. Scaling today is about architecture, not algorithms, and it’s important to consider that architecture up front, before the architectural debt is so restrictive you’re stuck with whatever you have.
Honestly, Niantic Labs did a good job building for failure. Capacity failures were met with friendly messages rather than the default HTTP status code pages that I often encounter. They were humorous and easy for kids to read and understand (I know, because my 8 year old read it to us every 20 minutes). What they didn’t plan for was the perhaps unexpected success with which they were met. Which is a good reminder for everyone that building to scale is just as important to building to fail.
Because when you don’t, Team Rocket wins.
About the Author

Related Blog Posts
Why sub-optimal application delivery architecture costs more than you think
Discover the hidden performance, security, and operational costs of sub‑optimal application delivery—and how modern architectures address them.

Keyfactor + F5: Integrating digital trust in the F5 platform
By integrating digital trust solutions into F5 ADSP, Keyfactor and F5 redefine how organizations protect and deliver digital services at enterprise scale.

Architecting for AI: Secure, scalable, multicloud
Operationalize AI-era multicloud with F5 and Equinix. Explore scalable solutions for secure data flows, uniform policies, and governance across dynamic cloud environments.

Nutanix and F5 expand successful partnership to Kubernetes
Nutanix and F5 have a shared vision of simplifying IT management. The two are joining forces for a Kubernetes service that is backed by F5 NGINX Plus.

AppViewX + F5: Automating and orchestrating app delivery
As an F5 ADSP Select partner, AppViewX works with F5 to deliver a centralized orchestration solution to manage app services across distributed environments.

F5 NGINX Gateway Fabric is a certified solution for Red Hat OpenShift
F5 collaborates with Red Hat to deliver a solution that combines the high-performance app delivery of F5 NGINX with Red Hat OpenShift’s enterprise Kubernetes capabilities.