
Kubernetes is an open source system developed by Google for running and managing containerized microservices‑based applications in a cluster. People who use Kubernetes often need to make the services they create in Kubernetes accessible from outside their Kubernetes cluster.
Although Kubernetes provides built‑in solutions for exposing services, described in Exposing Kubernetes Services with Built‑in Solutions below, those solutions limit you to Layer 4 load balancing or round‑robin HTTP load balancing.
This post shows how to use NGINX Plus as an advanced Layer 7 load‑balancing solution for exposing Kubernetes services to the Internet, whether you are running Kubernetes in the cloud or on your own infrastructure.
We’ll assume that you have a basic understanding of Kubernetes (pods, services, replication controllers, and labels) and a running Kubernetes cluster. To learn more about Kubernetes, see the official Kubernetes user guide.
Exposing Kubernetes Services with Built‑In Solutions
Kubernetes offers several options for exposing services. Two of them – NodePort and LoadBalancer – correspond to a specific type of service. A third option, Ingress API, became available as a beta in Kubernetes release 1.1.
NodePort
Specifying the service type as NodePort makes the service available on the same port on each Kubernetes node. To expose the service to the Internet, you expose one or more nodes on that port. For high availability, you can expose multiple nodes and use DNS‑based load balancing to distribute traffic among them, or you can put the nodes behind a load balancer of your choice.
When incoming traffic hits a node on the port, it gets load balanced among the pods of the service. The load balancing that is done by the Kubernetes network proxy (kube-proxy) running on every node is limited to TCP/UDP load balancing.
LoadBalancer
Specifying the service type as LoadBalancer allocates a cloud load balancer that distributes incoming traffic among the pods of the service.
The LoadBalancer solution is supported only by certain cloud providers and Google Container Engine and not available if you are running Kubernetes on your own infrastructure. Further, Kubernetes only allows you to configure round‑robin TCP load balancing, even if the cloud load balancer has advanced features such as session persistence or request mapping.
Ingress API
Creating an Ingress resource enables you to expose services to the Internet at custom URLs (for example, service A at the URL /foo and service B at the URL /bar) and multiple virtual host names (for example, foo.example.com for one group of services and bar.example.com for another group). An Ingress controller consumes an Ingress resource and sets up an external load balancer.
An Ingress controller is not a part of a standard Kubernetes deployment: you need to choose the controller that best fits your needs or implement one yourself, and add it to your Kubernetes cluster. Many controller implementations are expected to appear soon, but for now the only available implementation is the controller for Google Compute Engine HTTP Load Balancer, which works only if you are running Kubernetes on Google Compute Engine or Google Container Engine. The Ingress API supports only round‑robin HTTP load balancing, even if the actual load balancer supports advanced features.
As of this writing, both the Ingress API and the controller for the Google Compute Engine HTTP Load Balancer are in beta.
Update – NGINX Ingress Controller for both NGINX and NGINX Plus is now available in our GitHub repository. For product details, see NGINX Ingress Controller.
Although the solutions mentioned above are simple to set up, and work out of the box, they do not provide any advanced features, especially features related to Layer 7 load balancing.
Exposing Kubernetes Services with NGINX Plus
[Editor – This section has been updated to refer to the NGINX Plus API, which replaces and deprecates the separate dynamic configuration module originally discussed here.]
To integrate NGINX Plus with Kubernetes we need to make sure that the NGINX Plus configuration stays synchronized with Kubernetes, reflecting changes to Kubernetes services, such as addition or deletion of pods. With NGINX Open Source, you manually modify the NGINX configuration file and do a configuration reload. With NGINX Plus, there are two ways to update the configuration dynamically:
- With APIs – This method uses the NGINX Plus API to add and remove entries for Kubernetes pods in the NGINX Plus configuration, and the Kubernetes API to retrieve the IP addresses of the pods. This method requires us to write some code, and we won’t discuss it in depth here. For details, watch Kelsey Hightower’s webinar, Bringing Kubernetes to the Edge with NGINX Plus, in which he explores the APIs and creates an application that utilizes them.
- By re‑resolving DNS names – This method requires only a proper one‑time configuration of NGINX Plus, as described in the following section.
Utilizing DNS‑Based Reconfiguration
We assume that you already have a running Kubernetes cluster and a host with the kubectl utility available for managing the cluster; for instructions, see the Kubernetes getting started guide for your cluster type. You also need to have built an NGINX Plus Docker image, and instructions are available in Deploying NGINX and NGINX Plus with Docker on our blog.
Here is an outline of what we’ll do:
- Configure an NGINX Plus pod to expose and load balance the service that we’re creating in Step 2.
- Create a simple web application as our service.
- Scale the service up and down and watch how NGINX Plus gets automatically reconfigured.
Notes: We tested the solution described in this blog with Kubernetes 1.0.6 running on Google Compute Engine and a local Vagrant setup, which is what we are using below.
In commands, values that might be different for your Kubernetes setup appear in italics.
Configuring the NGINX Plus Pod
We are putting NGINX Plus in a Kubernetes pod on a node that we expose to the Internet. Our pod is created by a replication controller, which we are also setting up. Our Kubernetes‑specific NGINX Plus configuration file resides in a folder shared between the NGINX Plus pod and the node, which makes it simpler to maintain.
Choosing a Node to Host the NGINX Plus Pod
To designate the node where the NGINX Plus pod runs, we add a label to that node. We get the list of all nodes by running:
We choose the first node and add a label to it by running:
Configuring the Replication Controller for the NGINX Plus Pod
We are not creating an NGINX Plus pod directly, but rather through a replication controller. We configure the replication controller for the NGINX Plus pod in a Kubernetes declaration file called nginxplus-rc.yaml.
- We set the number of
replicasto one, which means Kubernetes makes sure that one NGINX Plus pod is always running: if the pod fails, it is replaced by a new pod. - In the
nodeSelectorfield we specify that the NGINX Plus pod is created on a node labeled withrole:nginxplus. - Our NGINX Plus container exposes two ports, 80 and 8080, and we set up a mapping between them and ports 80 and 8080 on the node.
- Our NGINX Plus container also shares the /etc/nginx/conf.d folder that resides on the node. As explained further in Configuring NGINX Plus below, sharing the folder lets us reconfigure NGINX Plus without rebuilding the container image.
Making the NGINX Plus Docker Image Available on the Node
As we said above, we already built an NGINX Plus Docker image. Now we make it available on the node. For simplicity, we do not use a private Docker repository, and we just manually load the image onto the node.
On the host where we built the Docker image, we run the following command to save the image into a file:
We transfer nginxplus.tar to the node, and run the following command on the node to load the image from the file:
Configuring NGINX Plus
In the NGINX Plus container’s /etc/nginx folder, we are retaining the default main nginx.conf configuration file that comes with NGINX Plus packages. The include directive in the default file reads in other configuration files from the /etc/nginx/conf.d folder. As specified in the declaration file for the NGINX Plus replication controller (nginxplus-rc.yaml), we’re sharing the /etc/nginx/conf.d folder on the NGINX Plus node with the container. The sharing means we can make changes to configuration files stored in the folder (on the node) without having to rebuild the NGINX Plus Docker image, which we would have to do if we created the folder directly in the container. We put our Kubernetes‑specific configuration file (backend.conf) in the shared folder.
First, let’s create the /etc/nginx/conf.d folder on the node.
Then we create the backend.conf file there and include these directives:
resolver– Defines the DNS server that NGINX Plus uses to periodically re‑resolve the domain name we use to identify our upstream servers (in theserverdirective inside theupstreamblock, discussed in the next bullet). We identify this DNS server by its domain name, kube-dns.kube-system.svc.cluster.local. Thevalidparameter tells NGINX Plus to send the re‑resolution request every five seconds. (Note that the resolution process for this directive differs from the one for upstream servers: this domain name is resolved only when NGINX starts or reloads, and NGINX Plus uses the system DNS server or servers defined in the /etc/resolv.conf file to resolve it.)upstream– Creates an upstream group called backend to contain the servers that provide the Kubernetes service we are exposing. Rather than list the servers individually, we identify them with a fully qualified hostname in a singleserverdirective. Theresolveparameter tells NGINX Plus to re‑resolve the hostname at runtime, according to the settings specified with theresolverdirective. Because both Kubernetes DNS and NGINX Plus (R10 and later) support DNS Service (SRV) records, NGINX Plus can get the port numbers of upstream servers via DNS. We include theserviceparameter to have NGINX Plus requestSRVrecords, specifying the name (_http) and the protocol (_tcp) for the ports exposed by our service. We declare those values in the webapp-svc.yaml file discussed in Creating the Replication Controller for the Service below. For more information about service discovery with DNS, see Using DNS for Service Discovery with NGINX and NGINX Plus on our blog.server(twice) – Define two virtual servers:- The first server listens on port 80 and load balances incoming requests for /webapp (our service) among the pods running service instances. We also set up active health checks.
- The second server listens on port 8080. Here we set up live activity monitoring of NGINX Plus. Later we will use it to check that NGINX Plus was properly reconfigured. [Editor – The configuration for this second server has been updated to use the NGINX Plus API, which replaces and deprecates the separate status module originally used.]
Creating the Replication Controller
Now we’re ready to create the replication controller by running this command:
To verify the NGINX Plus pod was created, we run:
We are running Kubernetes on a local Vagrant setup, so we know that our node’s external IP address is 10.245.1.3 and we will use that address for the rest of this example. If you are running Kubernetes on a cloud provider, you can get the external IP address of your node by running:
If you are running on a cloud, do not forget to set up a firewall rule to allow the NGINX Plus node to accept incoming traffic. Refer to your cloud provider’s documentation.
We can check that our NGINX Plus pod is up and running by looking at the NGINX Plus live activity monitoring dashboard, which is available on port 8080 at the external IP address of the node (so http://10.245.1.3:8080/dashboard.html in our case). If we look at this point, however, we do not see any servers for our service, because we did not create the service yet.

Creating a Simple Kubernetes Service
Now it’s time to create a Kubernetes service. Our service consists of two web servers that each serve a web page with information about the container they are running in.
Creating the Replication Controller for the Service
First we create a replication controller so that Kubernetes makes sure the specified number of web server replicas (pods) are always running in the cluster. Here is the declaration file (webapp-rc.yaml):
Our controller consists of two web servers. We declare a controller consisting of pods with a single container, exposing port 80. The nginxdemos/hello image will be pulled from Docker Hub.
To create the replication controller we run the following command:
To check that our pods were created we can run the following command. We use the label selector app=webapp to get only the pods created by the replication controller in the previous step:
Creating the Service
Next we create a service for the pods created by our replication controller. We declare the service with the following file (webapp-service.yaml):
Here we are declaring a special headless service by setting the ClusterIP field to None. With this type of service, a cluster IP address is not allocated and the service is not available through the kube proxy. A DNS query to the Kubernetes DNS returns multiple A records (the IP addresses of our pods).
We also declare the port that NGINX Plus will use to connect the pods. In addition to specifying the port and target port numbers, we specify the name (http) and the protocol (TCP). We use those values in the NGINX Plus configuration file, in which we tell NGINX Plus to get the port numbers of the pods via DNS using SRV records.
By setting the selector field to app: webapp, we declare which pods belong to the service, namely the pods created by our NGINX replication controller (defined in webapp-rc.yaml).
We run the following command, which creates the service:
Now if we refresh the dashboard page and click the Upstreams tab in the top right corner, we see the two servers we added.
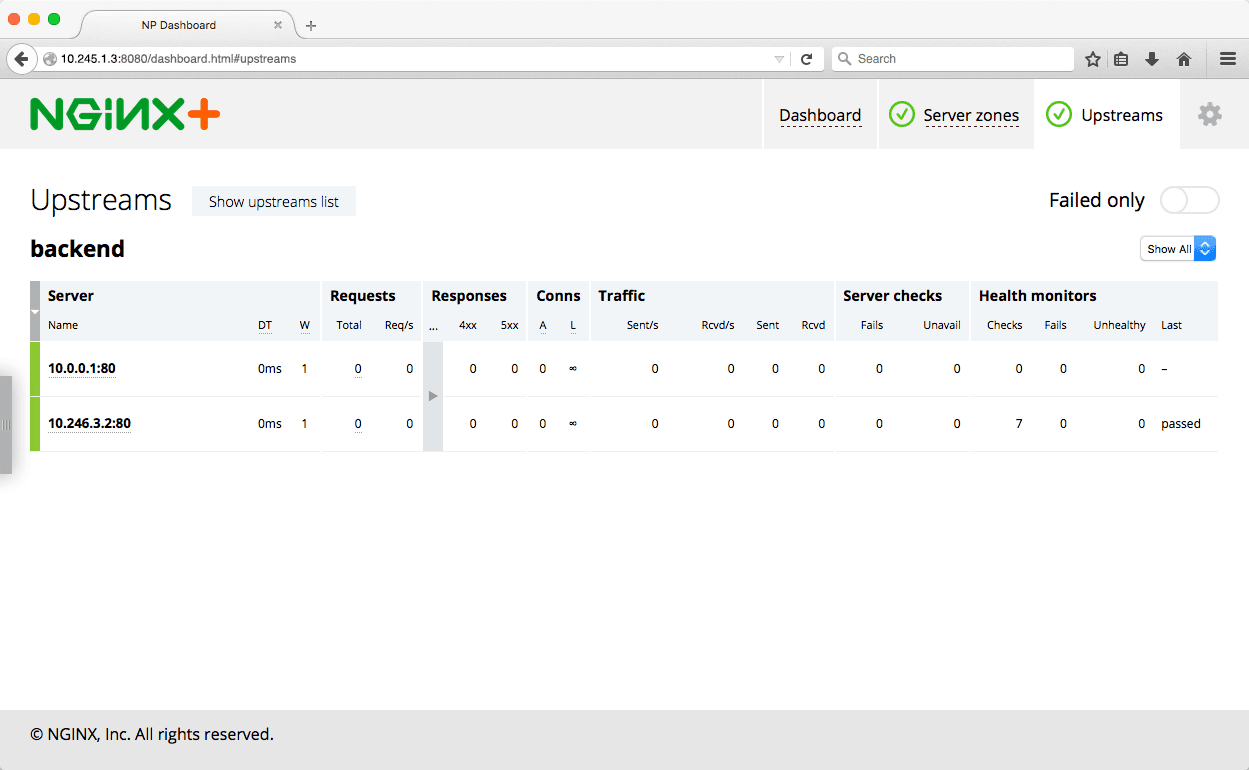
We can also check that NGINX Plus is load balancing traffic among the pods of the service. If it is, when we access http://10.245.1.3/webapp/ in a browser, the page shows us the information about the container the web server is running in, such as the hostname and IP address.
If we refresh this page several times and look at the status dashboard, we see how the requests get distributed across the two upstream servers.
Scaling the Kubernetes Service
[Editor – This section has been updated to use the NGINX Plus API, which replaces and deprecates the separate status module originally used.]
Now let’s add two more pods to our service and make sure that the NGINX Plus configuration is again updated automatically. We run this command to change the number of pods to four by scaling the replication controller:
To check that NGINX Plus was reconfigured, we could again look at the dashboard, but this time we use the NGINX Plus API instead. We run the following command, with 10.245.1.3 being the external IP address of our NGINX Plus node and 3 the version of the NGINX Plus API. To neatly format the JSON output, we pipe it to jq.
The peers array in the JSON output has exactly four elements, one for each web server.
Now let’s reduce the number of pods from four to one and check the NGINX Plus status again:
Now the peers array in the JSON output contains only one element (the output is the same as for the peer with ID 1 in the previous sample command).
Now that we have NGINX Plus up and running, we can start leveraging its advanced features such as session persistence, SSL/TLS termination, request routing, advanced monitoring, and more.
Summary
The on‑the‑fly reconfiguration options available in NGINX Plus let you integrate it with Kubernetes with ease: either programmatically via an API or entirely by means of DNS. Using NGINX Plus for exposing Kubernetes services to the Internet provides many features that the current built‑in Kubernetes load‑balancing solutions lack.
To explore how NGINX Plus works together with Kubernetes, start your free 30-day trial today or contact us to discuss your use case.
About the Author
Related Blog Posts

Secure Your API Gateway with NGINX App Protect WAF
As monoliths move to microservices, applications are developed faster than ever. Speed is necessary to stay competitive and APIs sit at the front of these rapid modernization efforts. But the popularity of APIs for application modernization has significant implications for app security.

How Do I Choose? API Gateway vs. Ingress Controller vs. Service Mesh
When you need an API gateway in Kubernetes, how do you choose among API gateway vs. Ingress controller vs. service mesh? We guide you through the decision, with sample scenarios for north-south and east-west API traffic, plus use cases where an API gateway is the right tool.
Deploying NGINX as an API Gateway, Part 2: Protecting Backend Services
In the second post in our API gateway series, Liam shows you how to batten down the hatches on your API services. You can use rate limiting, access restrictions, request size limits, and request body validation to frustrate illegitimate or overly burdensome requests.
New Joomla Exploit CVE-2015-8562
Read about the new zero day exploit in Joomla and see the NGINX configuration for how to apply a fix in NGINX or NGINX Plus.
Why Do I See “Welcome to nginx!” on My Favorite Website?
The ‘Welcome to NGINX!’ page is presented when NGINX web server software is installed on a computer but has not finished configuring